
Why RAG Evaluation Matters
Evaluating RAG (Retrieval-Augmented Generation) systems has become increasingly critical as organizations move beyond proof-of-concept implementations to production-ready solutions that directly impact business outcomes. Unlike traditional software where success metrics are often binary, RAG systems present unique evaluation challenges due to their dual nature - they must excel at both retrieving relevant information and generating coherent, factually accurate responses. This complexity is compounded by the evolving landscape of RAG applications, where different use cases demand tailored evaluation approaches: customer service applications might prioritize answer relevance and helpfulness, while financial or healthcare applications require stringent factual accuracy and groundedness metrics. The subjective nature of evaluation criteria such as relevance, coherence, and factual accuracy makes it challenging to establish consistent standards, necessitating systematic experimentation frameworks like the one outlined in this blog to ensure reliable, measurable improvements in RAG performance.
The Snowflake AI Observability tutorial provides an excellent foundation for understanding how to evaluate RAG systems using TruLens within the Snowflake ecosystem. However, moving from a proof-of-concept to a production-ready experimentation pipeline requires a more systematic approach to running multiple experiments, tracking configurations, and comparing results at scale.
This blog post expands on the concepts introduced in the Snowflake AI Observability tutorial and demonstrates how to build a comprehensive RAG experimentation pipeline that enables teams to iterate rapidly and optimize their systems with confidence. Well-structured experimentation empowers organizations to deliver higher-quality AI-powered products, boost productivity, and accelerate business outcomes by making data-driven improvements with every experiment.
Background: RAG in Snowflake
Before diving into evaluation strategies, let's briefly review how RAG systems work in Snowflake. For a comprehensive guide, see our detailed blog post on Leveraging Snowflake Cortex's Search to Build RAG Systems.
Data Ingestion and Processing
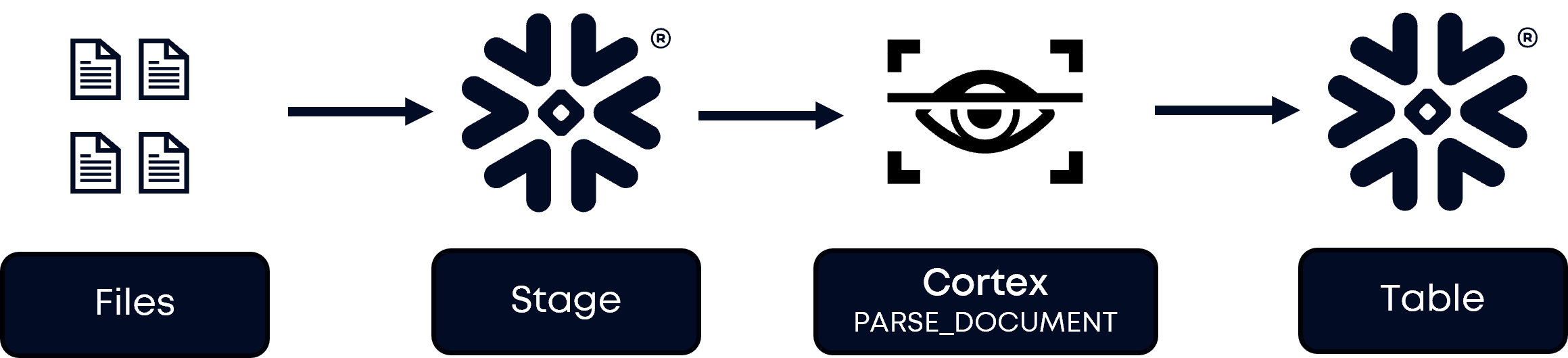
After ingesting your files into a Snowflake stage, the first step is to hand them off to Snowflake's Cortex PARSE_DOCUMENT function, which automatically processes various document formats and extracts structured information into Snowflake tables. This native capability eliminates the need for external preprocessing tools and ensures that your data remains within the secure Snowflake environment throughout the entire pipeline.
RAG Component Architecture
.png)
Snowflake Cortex provides native functions that simplify the implementation of RAG components. Chunking is the process of breaking large documents into smaller, manageable segments that can be effectively processed by embedding models and retrieved based on semantic similarity. SPLIT_TEXT_RECURSIVE_CHARACTER creates optimized chunks from your documents, while CREATE CORTEX SEARCH SERVICE establishes a vector database for similarity search. Cortex Search performs the actual retrieval operations, and Cortex COMPLETE generates responses based on retrieved context.
RAG System Evaluation Framework
In any production-ready machine learning system, ongoing evaluation is essential to maintain high performance as data and requirements evolve. Retrieval-Augmented Generation (RAG) systems are no exception—especially since new documents are frequently ingested into their pipelines. To ensure reliability and effectiveness in real-world applications, RAG systems must be evaluated at two distinct levels: retrieval performance and generation quality (as seen in Figure 2 above). Each level has specific metrics and tuning parameters that directly impact overall system effectiveness.
Retrieval performance is controlled by several key parameters:
i. Chunking Strategy: How documents are segmented affects context quality
ii. Embedding Model Selection: Vector representation quality impacts search accuracy
iii. Retrieval Configuration: Search parameters that control result quality
Generation quality is optimized through:
i. LLM Model Selection: Different models excel at various tasks
ii. Prompt Engineering: How instructions are crafted affects output quality
The RAG Triad Methodology: Why It Matters
The RAG Triad methodology (Figure 3) is a holistic evaluation framework for RAG systems, assessing three critical dimensions: Context Relevance, Groundedness, and Answer Relevance. This triad ensures that both the retrieval and generation components of a RAG pipeline are systematically evaluated, enabling targeted improvements and reliable performance.
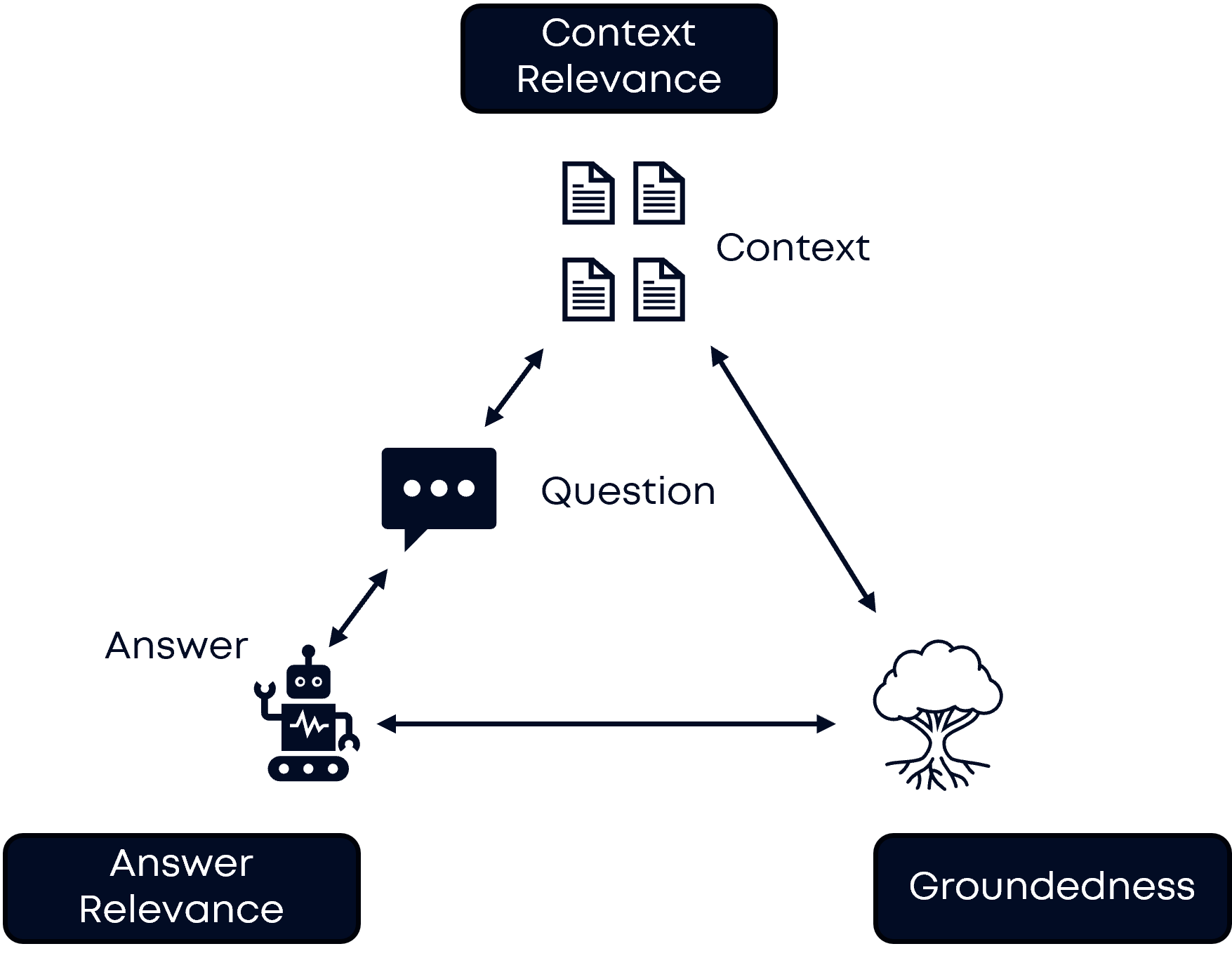
Why Does the RAG Triad Matter?
- Holistic Evaluation: By covering both retrieval (Context Relevance) and generation (Groundedness and Answer Relevance), the triad ensures the entire RAG system is assessed, not just isolated components.
- Targeted Optimization: If issues are found in context relevance, retrieval strategies (like chunking or embeddings) can be improved. If groundedness or answer relevance scores are low, prompt engineering or model selection can be addressed.
- Reliable Answers: High scores across all three dimensions mean the system retrieves the right documents, grounds its answers in those documents, and directly addresses the user’s question, leading to trustworthy and actionable outputs.
Why Each Dimension Matters
- Context Relevance: Measures whether the retrieved chunks are pertinent to the input query. If context relevance is high, it means the system is finding the right documents to answer the question, which is foundational for accurate and useful responses.
- Groundedness: Assesses if the generated answer is factually supported by the retrieved context. High groundedness ensures the model isn’t hallucinating or inventing information, but is instead anchored in real retrieved data.
- Answer Relevance: Evaluates whether the final answer addresses the original user question. This ensures that, even if context and grounding are strong, the answer remains focused and useful for the user’s intent.
Example Formulas for RAG Triad Metrics
Below are typical formulas used to quantify each dimension:
i. Context Relevance (CR):
ii. Groundedness (G):
iii. Answer Relevance (AR):
Conclusion
As we’ve explored in this first part, building robust Retrieval-Augmented Generation (RAG) systems in Snowflake requires a deep understanding of both the architecture and the unique evaluation challenges these systems present. By leveraging Snowflake’s native AI capabilities and adopting a systematic evaluation framework—especially the RAG Triad methodology—you can ensure your RAG pipelines are not only effective but also aligned with your organization’s specific business goals.
Understanding how to properly ingest, process, and evaluate data within Snowflake sets a strong foundation for success. With clear metrics for context relevance, groundedness, and answer relevance, your team can confidently assess RAG performance and identify targeted areas for optimization.
In the next installment, we’ll move from theory to practice—demonstrating how to set up experiment management schemas, run systematic experiments, and leverage Snowflake’s capabilities to build a scalable, production-ready RAG evaluation pipeline. Check out the next installment to learn how to turn these insights into actionable improvements and measurable business value.
About Aimpoint Digital
Aimpoint Digital is a market-leading analytics firm at the forefront of solving the most complex business and economic challenges through data and analytical technology. From integrating self-service analytics to implementing AI at scale and modernizing data infrastructure environments, Aimpoint Digital operates across transformative domains to improve the performance of organizations. Connect with our team and get started today.



.png)