
Introduction
In Part 1 of this series, we explored the foundational concepts behind evaluating Retrieval-Augmented Generation (RAG) systems in Snowflake—covering the unique challenges of RAG evaluation, the importance of the RAG Triad methodology, and the architectural building blocks that underpin a robust pipeline. Now, it’s time to move from theory to practice.
In this second installment, we’ll guide you step-by-step through the process of transforming these foundational insights into a production-ready experimentation pipeline. You’ll learn how to design experiment management schemas, systematically run and track multiple RAG experiments, and interpret results to drive measurable improvements. We’ll also share best practices for aligning your experimentation approach with your organization’s business goals—whether you’re aiming to minimize hallucinations, maximize answer coverage, or deliver concise, highly relevant responses.
By leveraging Snowflake’s native AI capabilities, you’ll discover how to accelerate your RAG experimentation cycles, ensure enterprise-grade security, and seamlessly scale from proof-of-concept to production. Whether you’re an AI engineer, data scientist, or business leader, this guide will equip you with the tools and strategies needed to build, evaluate, and optimize RAG systems that deliver real business value.
Let’s dive in and turn RAG experimentation into your organization’s competitive advantage.
Creating the Experiment Management Schema
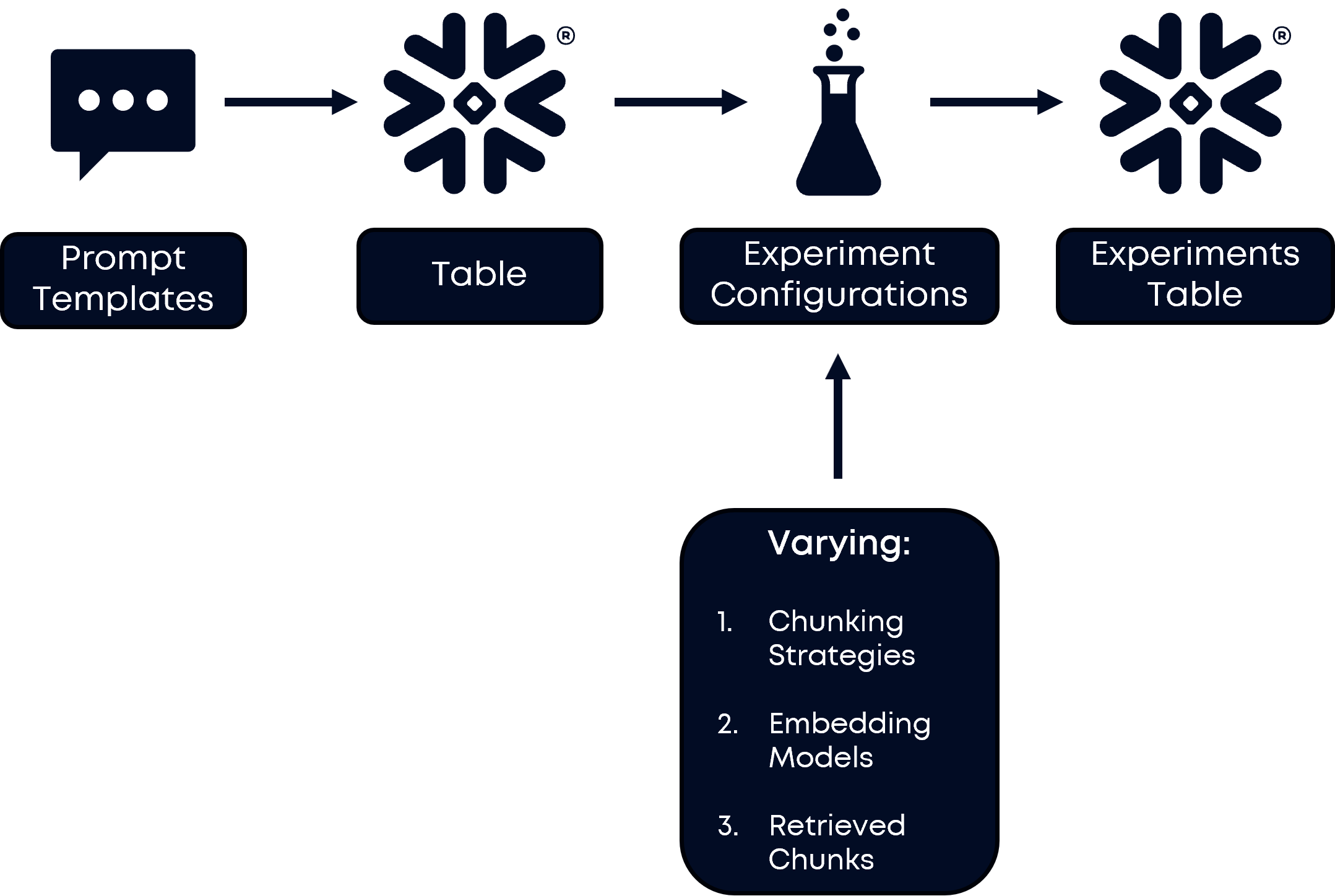
To effectively manage multiple experiments, you'll need a robust schema that tracks both configurations and results. The foundational structure should include tables for experiments, experiment runs, and evaluation results.
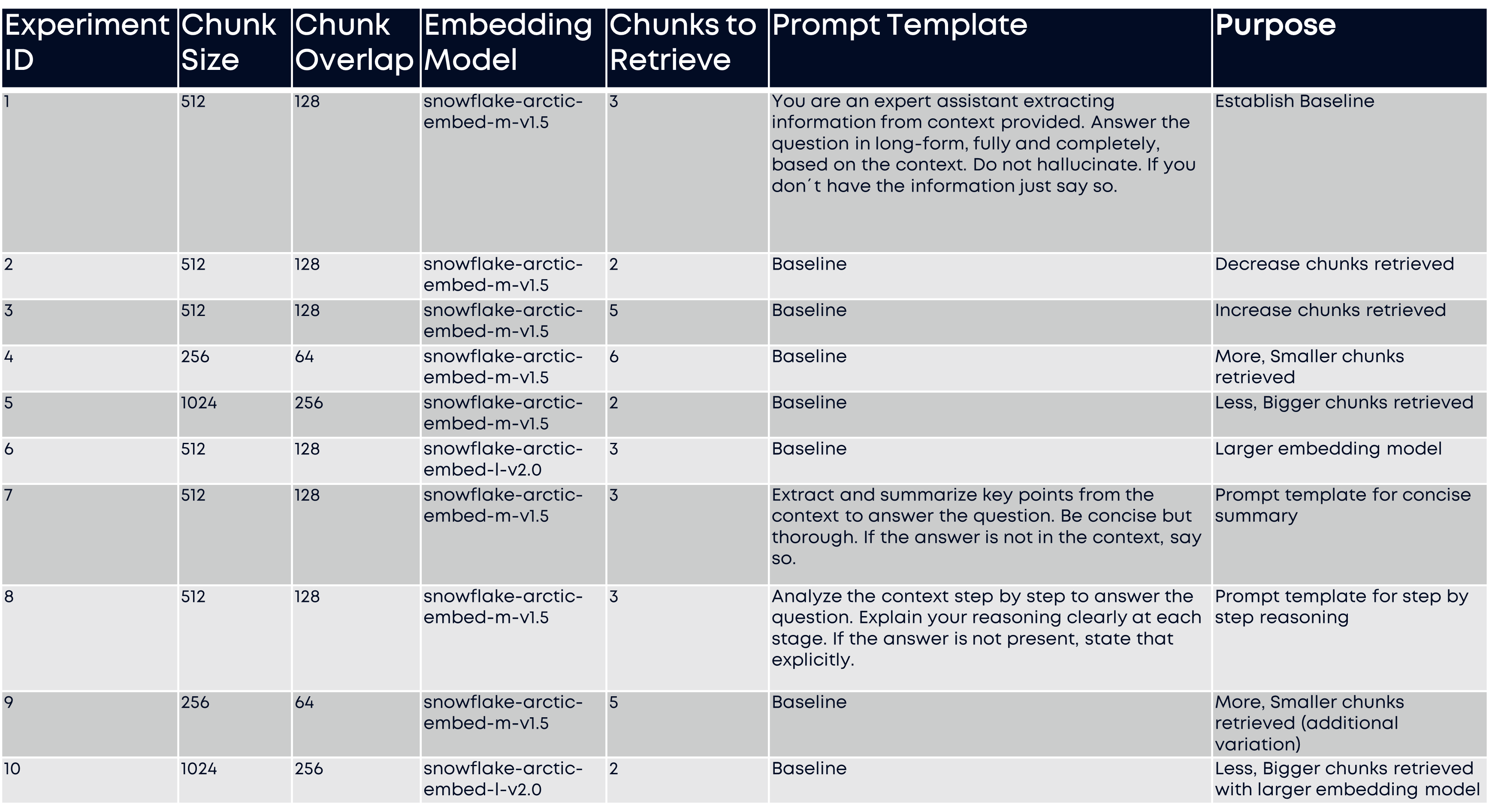
Table 1 above shows an example experiment configuration we used to test the FOMC data from Snowflake’s AI Observability tutorial.
Implementing Systematic Experimentation
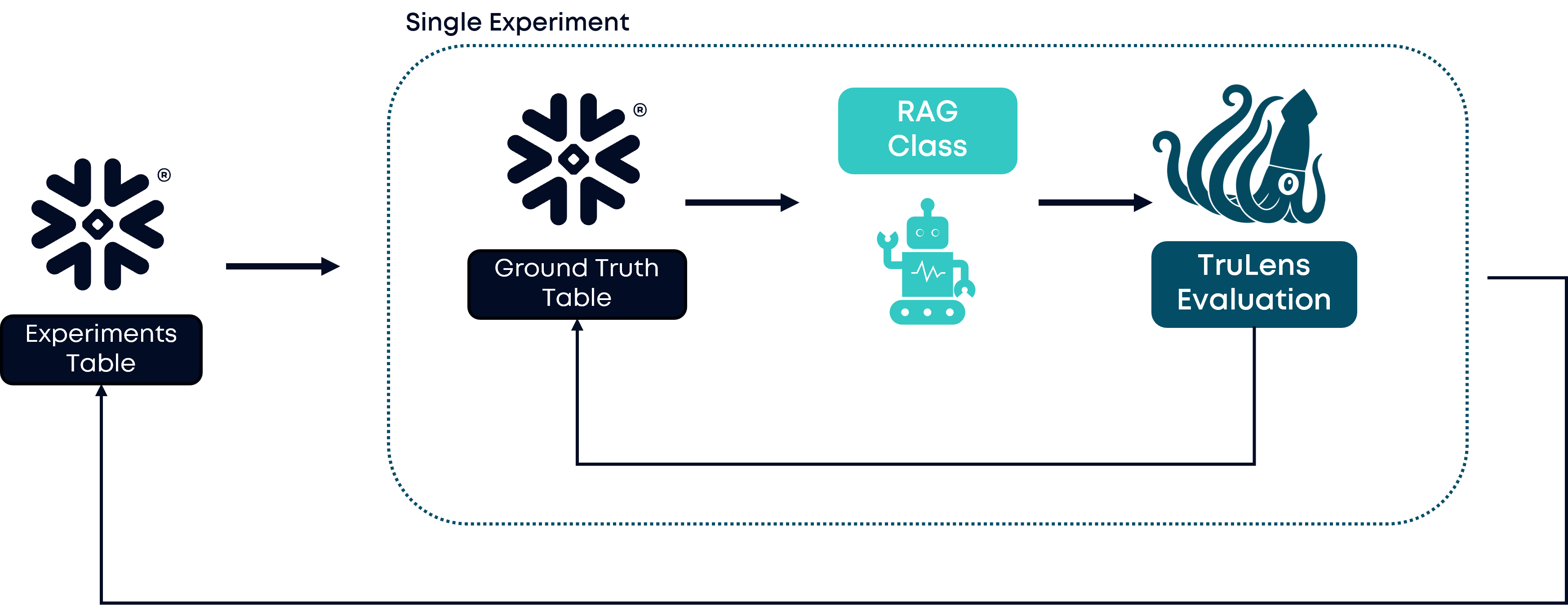
Based on our experience with RAG systems, a practical approach involves setting up multiple experiments that test key performance variables systematically. (See Table 1 for an example).
This configuration matrix allows you to systematically test the impact of different parameters while maintaining control variables for meaningful comparisons. Each experiment focuses on a specific aspect such as: baseline performance, semantic chunking effectiveness, model comparisons, chunk size optimization, embedding model selection, and large context handling.
.png)
Recommendations Based on Organizational Goals
- If Your Goal is to Minimize Hallucinations: Prioritize configurations that maximize the groundedness metric like experiment 2. A higher groundedness score means the generated answers are factually supported by the retrieved context as compared to other experiment runs, reducing the risk of hallucinations.
- If Your Goal is Comprehensive Coverage: Opt for configurations that maximize answer relevance and correctness like experiment 3. This often means retrieving more chunks or expanding the search window, ensuring the answer addresses all facets of the user’s query.
- If Your Goal is Precision and Conciseness: Use configurations that maximize context relevance like experiments 5 or 10 – typically, fewer but larger chunks that are highly relevant to the query. This approach is best when users value succinct, on-point responses.
Leverage Snowflake's Native Capabilities for Competitive Advantage
Organizations implementing RAG evaluation in Snowflake gain significant strategic advantages that directly impact their bottom line and operational efficiency. Unlike fragmented toolchains that require complex integrations and data movement, Snowflake's unified platform delivers measurable business outcomes.
Accelerated Time-to-Value
Traditional RAG experimentation often takes weeks or months due to infrastructure setup, data pipeline creation, and tool integration challenges. Snowflake's native capabilities reduce this timeline to days or hours. Organizations can iterate on RAG configurations rapidly, testing multiple parameter combinations without the overhead of managing separate vector databases, compute clusters, or evaluation frameworks.
Enterprise-Grade Security and Compliance
For regulated industries like healthcare, finance, and government, data governance isn't optional—it's critical. Snowflake's role-based access control ensures that sensitive evaluation data never leaves the secure perimeter, while maintaining full audit trails for compliance requirements. This eliminates the risk and complexity of moving proprietary data through external evaluation tools.
Cost Optimization Through Intelligent Resource Management
Snowflake's automatic scaling handles large evaluation datasets efficiently, spinning up compute resources only when needed.
Production-Ready Scalability from Day One
The seamless transition from experimentation to production deployment means that evaluation insights immediately translate into operational improvements. Teams can confidently deploy optimized RAG configurations knowing they've been tested at enterprise scale within the same environment where they'll run in production.
The Strategic Imperative
In today's AI-driven landscape, the organizations that can iterate fastest on their RAG systems will capture the most value. Snowflake's native capabilities don't just make evaluation easier—they make it a competitive differentiator. While competitors struggle with complex toolchains and data movement challenges, your organization can focus on what matters: optimizing AI performance to drive business outcomes.
This integrated approach transforms RAG evaluation from a technical hurdle into a strategic capability, enabling continuous improvement cycles that keep your AI applications ahead of the competition.
Aimpoint Digital's Proven Approach
At Aimpoint Digital, we've successfully implemented RAG experimentation pipelines for numerous clients across various industries. Our approach emphasizes rapid prototyping using Snowflake's native AI capabilities, systematic evaluation using the RAG Triad methodology, production-ready scalable architectures that handle enterprise workloads, and comprehensive knowledge transfer to ensure teams can maintain and extend the solutions.
Our RAG PoC accelerator includes pre-built experiment frameworks, evaluation templates, and best practice guidelines that reduce time-to-value while ensuring robust, production-ready implementations. We've demonstrated this capability through solutions like SearchGPT, which utilizes AI, LLMs, and embedded vector databases to enable efficient document search across various file types while maintaining enterprise security requirements.
Conclusion
Building robust RAG systems requires more than just connecting components—it demands systematic experimentation, rigorous evaluation, and continuous optimization. By leveraging Snowflake's native AI capabilities alongside TruLens' evaluation framework, organizations can build experimentation pipelines that deliver measurable improvements in RAG performance.
The approach outlined in this blog post, from basic experiment setup to advanced optimization techniques, provides a roadmap for transforming the insights from Snowflake's Observability AI demo into production-ready solutions. Whether you're just beginning your RAG journey or looking to optimize existing systems, the combination of Snowflake Cortex and TruLens offers a powerful platform for achieving your AI objectives.
At Aimpoint Digital, we're committed to helping organizations unlock the full potential of their data through advanced AI solutions. Our expertise in RAG system development, combined with deep knowledge of the Snowflake ecosystem, enables us to deliver solutions that drive real business value while ensuring scalability, security, and maintainability.
Ready to implement RAG experimentation in your organization? Contact Aimpoint Digital to learn how our proven methodologies and accelerators can help you build production-ready RAG systems in Snowflake or your existing tech stack.



.png)