
What Are Regular Expressions?
Regular Expressions (more commonly known as RegEx) are a powerful tool in any data analyst’s arsenal, providing a means by which users can search and extract patterns from text strings.
Below are some simple examples of where RegEx can be useful:
- Extracting zip codes from address strings
- Removing special characters from strings
- Identifying hashtags and mentions in tweets
- Verifying email formats
This post will highlight some key ways in which Dataiku have integrated RegEx into their Data Science Studio (DSS) product.
Extracting and Matching Patterns Within Text Strings
Perhaps the most common use of RegEx for a data analyst is to extract data from a string. In Dataiku DSS, this is made possible via the ‘Extract with regular expression’ processor within the ‘Data Preparation’ recipe.
In this example, we are going to use Twitter data and look to parse out different pieces of information from tweets mentioning US airlines. We will use this processor configured in three ways to show its full capability.
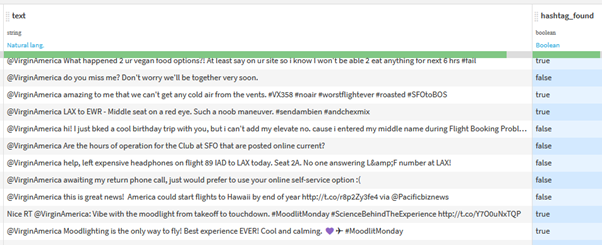
Firstly, we will look at flagging if a ‘hashtag’ is present within each tweet.

For this scenario, we must specify three things:
- The column with which we want to match our pattern against
- The prefix for the names of any output columns that are generated (you’ll see more as to why this is important in the final example we share)
- And, of course, our pattern is given in the ‘Regular expression’ box.
In this case, we have used the pattern ‘#\w+.’ The important thing to note here is that we have not denoted any brackets, which are used in RegEx to identify parts of the text we want to extract. No extraction will occur, but by specifying that we want to ‘Create a special ‘found’ column,’ we will only generate a field indicating if our pattern is contained within the tweet.
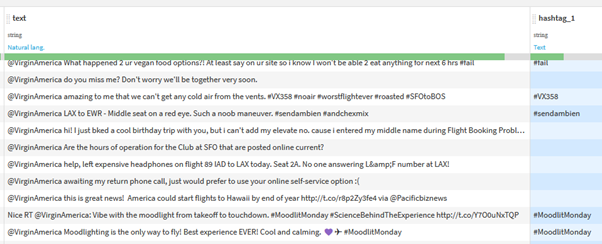
This scenario can be developed further; let’s say we actually want to extract the hashtags from our tweets.
A similar pattern can be used, but this time, by wrapping our pattern in brackets, we will inform Dataiku that we want to extract the pattern that was found.

Of course, you can choose whether the ‘special found column’ is still relevant.
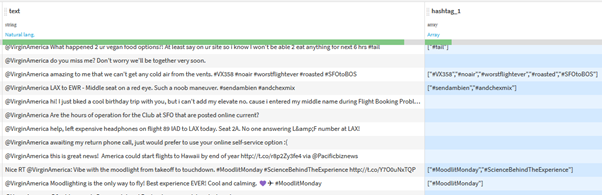
In this scenario, only one instance of our hashtag is extracted, even though in some tweets, there are multiple. To parse our pattern in a repeated way, we should use the ‘Extract all occurrences’ option.

This will result in our ‘hashtag_1’ column containing all our detected hashtags in an array format. If required, these can be parsed into individual columns (using the ‘Unnest Object’ processor) or individual rows (using the ‘Fold an array’ processor).
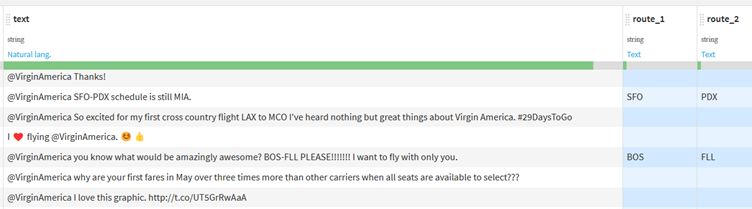
The last scenario we will look at is to try and extract route information if it is included in each tweet. This differs from our previous use case as we want to extract two different components from our tweets rather than just a single or repeated component.
Dataiku will create a new field, with your chosen prefix, for every marked group you give.

With this configuration, we can extract two (given we have two marked groups) three-character words before and after a dash (-): One of the common ways in which route information is displayed.
Applying Data Preparation Recipes to Multiple Fields
In the DSS data preparation recipe, a number of the processors (individual steps that you can apply) allow you to apply your desired transformation against a single column, multiple columns, or all columns. With each option, you must be explicit in setting the fields that you wish to apply your transformation against. However, there is an additional option ‘pattern.’ This functionality allows you to dynamically select the fields you wish to apply your processor against by matching the field names using a RegEx pattern.
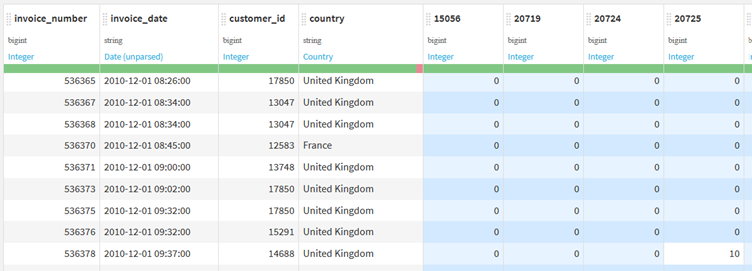
Let’s take the transactional sales data outlined below as an example.
In this dataset, each row is an individual order made by our customers. Each line has some basic information, such as the date of the sale, who the customer is, and from which country the order was made. We then have a column for each product we sell, which is populated by the quantity of that product sold if it were included in the order.
For example, ten units of product ‘20723’ were sold on order ‘536378’.
You will see in our table that the majority of the cells for each product are empty, but what if we want them to be 0 instead of empty? We can use the ‘Fill empty cells with fixed value’ processor to achieve this.

By specifying the ‘Column’ we wish to apply this to using the RegEx pattern ‘\d+,’ we can ensure that we only fill empty values with zero for columns where a column name is a product number. We also ensure that this transformation is applied to any new products that enter our dataset.
Dynamic Transpose
Another standard data preparation processor we may want to use with this dataset is to ‘fold’ our data, a technique also referred to as ‘pivoting’ or ‘transposing.’ The purpose is to transform our data from this ‘short and wide’ format into a ‘long and thin’ format whereby we have a single column representing our individual product numbers and a second column indicating the number of units sold, for that item, on the given order.
In Dataiku DSS, there are two processors that we may use in this scenario, one where you specify the specific fields that you are looking to fold and one where the columns you want to fold can be set dynamically via RegEx. This is the ‘Fold multiple columns by pattern’ processor.

Here we can use a pattern to specify that we want to fold any columns which look like a product number; the statement’ \d+’ will match any columns which are only numbers. Meaning that as new products are added to our data, then they too will be folded.
In the case of this tool, we also specify the ‘column for the fold name.’ This is the new field that will contain what was previously our column headers (product numbers). The ‘column for fold value‘ represents the field’s name, including our quantity values.
Finally, we have the option to remove the folded columns from our dataset. In this case, we will check this option, which means all the original product columns will be removed after the fold has been implemented.
As you can see, we have successfully transformed our dataset from wide to long format in a dynamic way, using RegEx.
Building RegEx with 'Smart Pattern Builder'
Dataiku DSS’ Smart Pattern Builder provides Data Analysts with a way to easily curate the patterns required to extract their desired text. This feature is available in both the ‘Extract with regular expression’ and ‘Fold multiple columns by pattern’ processors.

By selecting the ‘Smart Pattern’ option in the confirmation window for the processor, the ‘Smart Pattern Builder’ will open. This window allows users to provide examples of the text they wish to extract (based on their actual data). Dataiku will then automatically generate the RegEx pattern required to extract this text.
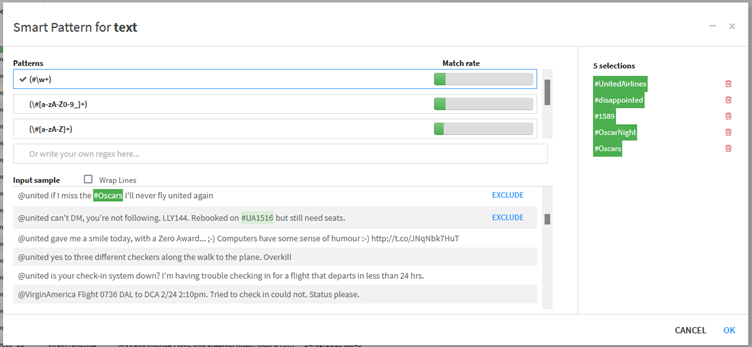
The ‘Smart Pattern Builder’ will also highlight to users how much of their data will be successfully parsed for each proposed expression. This functionality can also be accessed directly from the data grid in a prepared recipe by highlighting a specific part of a text string. Upon right-clicking, the option ‘Extract text like …’ will be presented to the user. Once the pattern has been set, an ‘Extract with regular expression’ step will automatically be added to the Data Preparation recipe.
In this blog post, we have highlighted four ways you can work with RegEx within Dataiku DSS. We challenge you to use these tools to help you build robust and flexible data pipelines.
Get in Touch With Aimpoint Digital for Assistance
Aimpoint Digital’s data experts are always here to help if you need assistance. Please get in touch with us through the form below.


.png)
