
What is data modeling in Sigma?
Sigma’s Data Model feature offers a centralized, reusable data modeling layer that separates business logic from visualizations. This allows your team to define relationships, standardize metrics, and apply security rules in one place—ensuring everyone is working from the same trusted foundation.
Imagine you're a sales analyst creating weekly revenue reports. Each week, you connect to warehouse tables, join customer and orders data, calculate totals, and clean up field names. It’s repetitive, time-consuming, and often done differently by each person on the team.
Sigma’s Data Model feature eliminates this inefficiency. You can join tables, define calculations, apply column- and row-level security, and publish the model for use across dashboards and users—without writing complex code. The result is faster time to insight and consistent business logic that’s easy to maintain and scale. In the following section, we’ll explore some of the key features in Sigma’s Data Model that make this possible, starting with how it handles relationships and joins.
Key features
Relationships & Joins
Data in your warehouse often lives across multiple tables. You might have separate tables for customers, orders, and products, each with its own structure and level of detail. In Sigma, the Data Model feature gives you two powerful options for combining that data: you can join tables together directly within the model, or you can define relationships that let others combine the data later, without needing to recreate the join logic themselves.
Joins are useful when you want to create a single, unified dataset for a specific use case. Relationships, on the other hand, preserve the original table structures while making them available to downstream users. For example, by defining a relationship between Orders and Customers on customer_id, you enable analysts to work with fields from both tables in their analysis without having to define the underlying join. This saves time, reduces errors, and helps ensure the use of consistent logic across your team’s work.
You can also explore these relationships visually through the Entity Relationship Diagram in the data modeling interface. This provides a clear, interactive view of how your tables are connected, helping both data teams and business users understand the structure of the model.
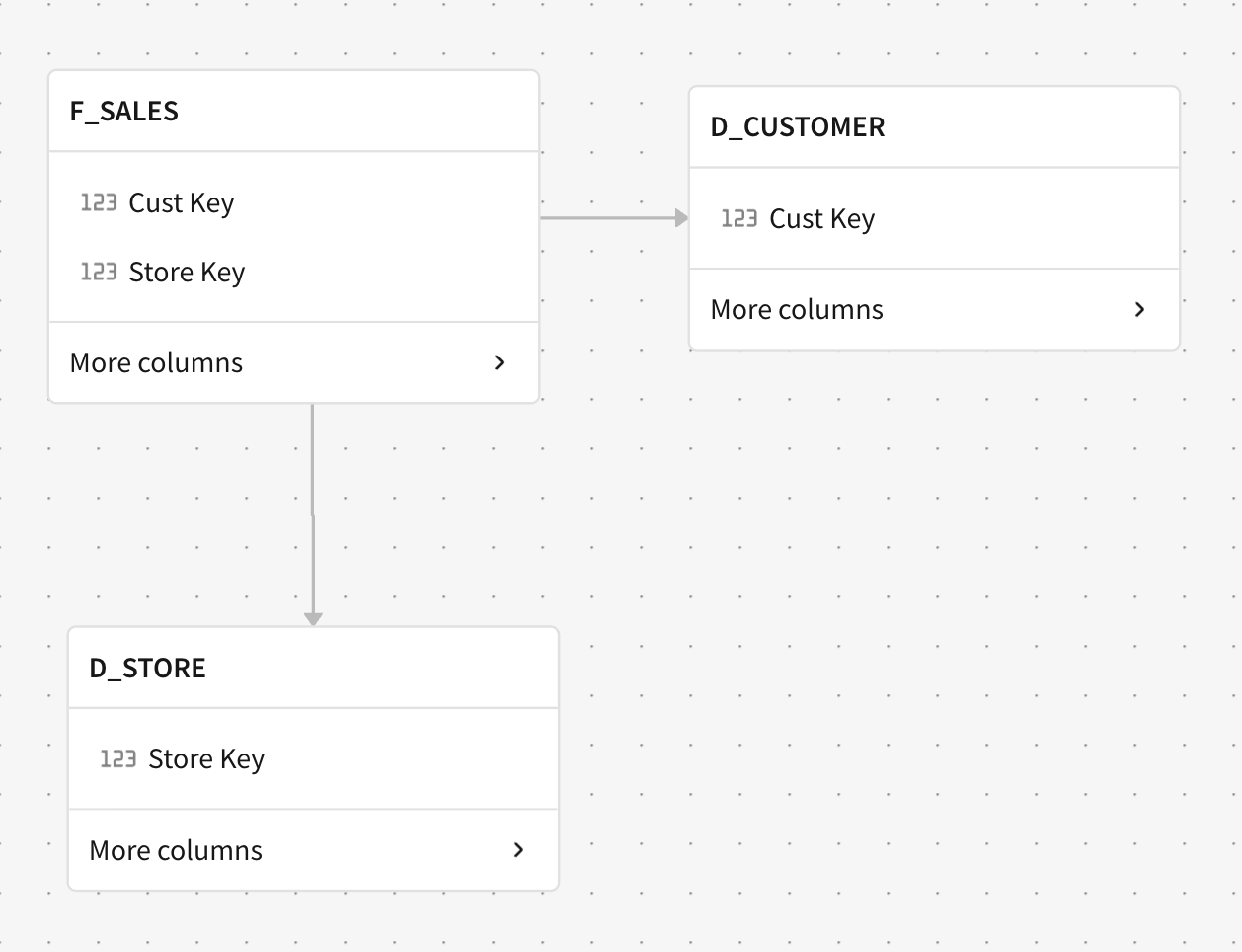
Figure 1: A screenshot of an Entity Relationship Diagram in Sigma illustrating the relationships between 3 different tables.
Lineage
When something in your dashboard looks off, understanding how the data objects are related can save hours of troubleshooting. Sigma’s lineage view provides a visual map showing how elements such as models, tables, and charts relate to one another. It shows which models feed into which workbooks and how different components within Sigma are linked.
The lineage view is especially useful with the Data Model feature. It helps you quickly see how tables are joined and which elements were created as child elements. This makes it easier to understand the structure of a data model at a glance, which supports faster onboarding, easier validation, and smoother change management.

Figure 2: A screenshot of the lineage view in a data model while in edit mode.
It also plays an important role in governance. When updating a model, the lineage tab (available when viewing the details of any element in a data model) shows which workbooks reference that element. This helps you identify what content might be affected, so you can make changes with clarity and control.

Figure 3: A screenshot of the lineage view of a Sigma table while viewing a published data model.
Metrics
With Sigma, you can define key business metrics directly within a data model, ensuring that your definitions are consistent, your logic is transparent, and your team stays aligned. Rather than retyping formulas or copying calculations across workbooks, you create metrics once and reuse them wherever needed.
For example, you might define Gross Margin as (Revenue - COGS) / Revenue in a data model. Analysts across Sales, Finance, and Operations can then use that same metric in their analysis without needing to recalculate it or risk introducing inconsistencies. This reduces duplicative effort, simplifies collaboration, and gives everyone a single source of truth for decision-making.

Figure 4: A screenshot of a metric viewed in a data model.
Security
Sigma makes it easy to collaborate across teams while maintaining control over what each user can see. With column- and row-level security, you can restrict access to specific fields or records within a data model based on a user’s role or team. This allows you to expose a single model to multiple audiences without having to create separate versions of the data.
For example, you might grant Finance access to revenue and margin fields while hiding those same columns from the Operations team. You can also use column-level security to restrict access to personally identifiable information (PII), such as employee names or contact details, ensuring that sensitive data is only visible to authorized users. The underlying data stays the same, but users only see what they are permitted to see when they interact with a workbook or explore the model. This approach supports consistent logic and reduces duplication, while keeping sensitive information protected.
Column-level security is defined at the model level, which means it applies wherever the model is used. This allows data teams to manage access centrally, ensuring compliance while still enabling broad, self-serve analytics across the business.

Figure 5: A screenshot of a column-level security configuration.
Row-level security works similarly. Rules defined in the model apply everywhere it's used, filtering data dynamically based on each user’s access. Row-level security is best implemented using filters tied to user attributes or team membership, making it easier to scale access controls and align them with your organization’s structure.
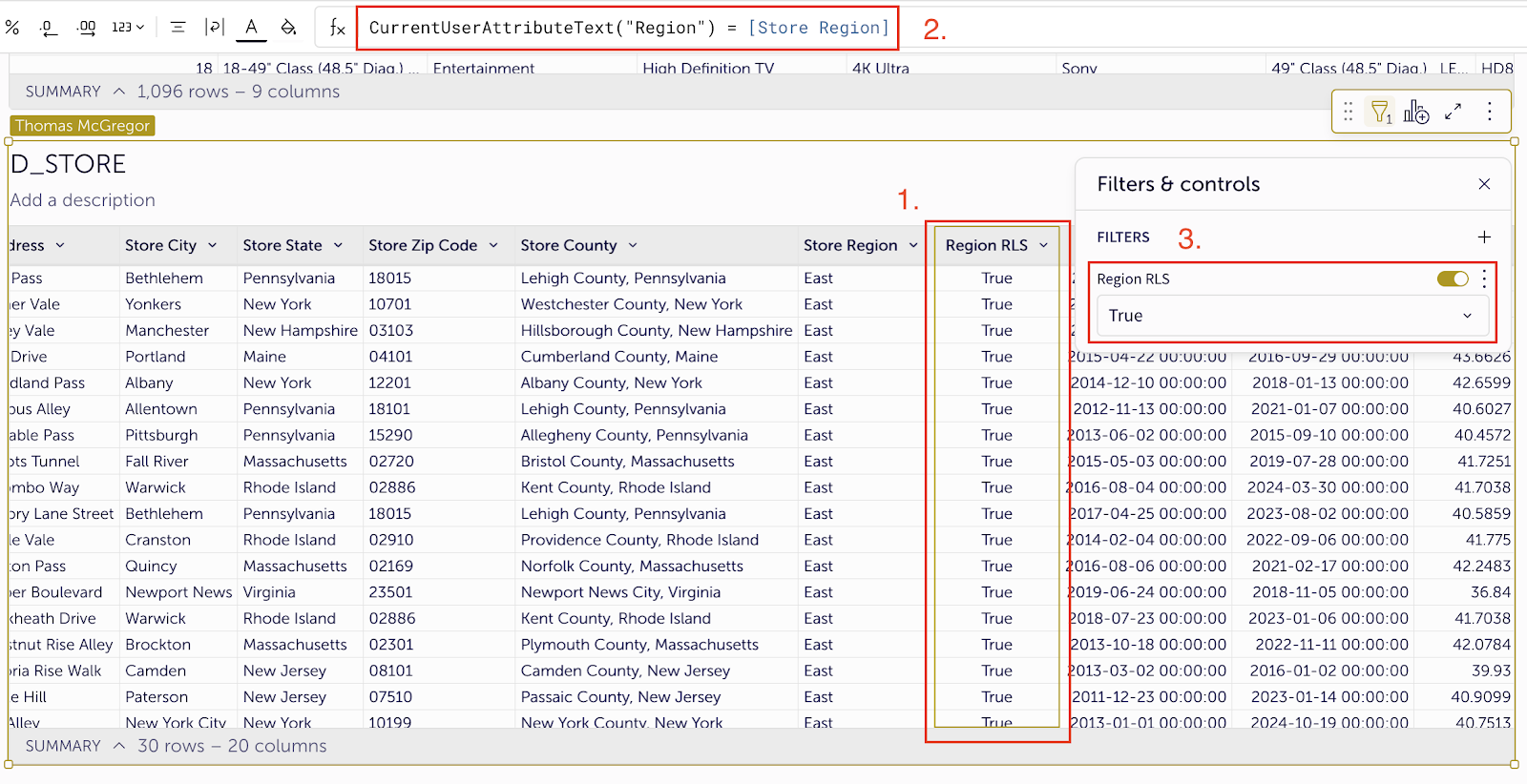
Figure 6: A screenshot of a row-level security setup in a data model.
Step 1: Create a new calculated column.
Step 2: Set the values to true if the Region user attribute of the current user is the same as the Store Region.
Step 3: Filter for records where the new column is equal to true.
How Sigma’s approach to data modeling is different
Unlike other BI tools, Sigma provides a single interface where you can connect to warehouse tables, perform operations like joins, filters, and calculations, create reusable models and explore and visualize data — all without leaving the browser. This unified interface streamlines workflows and reduces tool switching, making it easier for both technical and business users to collaborate on trusted data.
1. Reusable and composable models
- Sigma models can reference other models (like dbt’s ref function), allowing teams to:
- Break logic into modular layers (e.g., base_orders, filtered_orders, monthly_metrics)
- Reuse these across multiple dashboards or users without duplicating logic
- This composability enables version control, DRY (Don't Repeat Yourself) practices, and centralized metric definitions.
2. Live data at the warehouse layer
- Sigma's modeling happens directly on the cloud data warehouse, with no data extracts.
- This ensures models are live and scalable, tapping into the full performance and security of the warehouse (like Databricks, Snowflake or BigQuery).
- In contrast, other BI tools like Tableau and Power BI often require data extracts or caching, which can get stale or limited in scale.
3. Collaborative and code-free yet powerful
- Sigma’s modeling UI allows both technical teams (like Analytics Engineers) and business users to work together. Technical users can build complex logic, and business users can explore without writing SQL.
- This bridges the gap between data and business teams, reducing bottlenecks.
Data modeling best practices
Sigma’s Data Model layer is powerful, but it works best when used with care and consistency. The following Do's and Don'ts will help you create scalable, secure, and user-friendly models that can be confidently reused across your organization. For more background on how BI-layer modeling compares to database-level modeling, check out our blog post on Selecting Your Approach for Data Modeling.
1. Centralize your metrics
DO create metrics within your data model.
When key calculations like Gross Margin or Net Revenue are defined in the data model, they become standardized across teams. This removes the risk of each analyst calculating metrics slightly differently and ensures clarity on how each metric is derived.
Tip: Place important metrics at the top of the data model so they are easy to find.
2. Use Relationships to improve performance
DO use relationships over joins where possible.
Relationships defer joins until they are actually needed, often after filters are applied. This leads to more efficient queries and faster performance.
Example:
Create a relationship between Orders and Customers on customer_id. Filters applied to Orders will limit the data before any join takes place when columns from Customers are added in.
DON’T use self-joins or circular relationships.
Joining a table to itself or creating loops between tables can lead to ambiguous results, slow performance, or outright errors in your model.
Example:
Imagine a table called Employees with fields employee_id and manager_id, where each employee has a manager who is also listed in the same table. It might seem natural to join the Employees table to itself to retrieve manager names. However, this self-join can complicate the model, especially when multiple joins are involved elsewhere.
Better approach:
Instead of joining the table to itself, duplicate the Employees table in your data model and call it Managers. You can now join Employees to the duplicated Managers table using Employees.manager_id = Managers.employee_id. This avoids circular logic and keeps the model easier to understand and maintain.
3. Structure your model for flexibility
DO use “Pit Stop” tables.
Add a child table directly after your raw data source (also known as a “Pit Stop” table). This gives you a layer where you can rename columns, apply filters, or perform transformations without touching the source. It gives you more control as the model evolves.
Example:
Create a child table from your raw Transactions table. Apply standard naming conventions and flag invalid rows here before joining it to other tables.
DO organize your columns using folders.
Folders group related fields, such as "Customer Details" or "Order Metrics", helping users understand the layout and find what they need quickly.
DO hide supporting tables and columns.
If a table or field exists only to support joins or calculations, hide it. This reduces clutter and avoids confusion when others explore the model.
4. Secure your model by design
DO use column-level security (CLS) at the parent level.
Defining CLS at the top of the model ensures that all child elements follow the same rules. It is also easier to manage long-term.
Example:
Hide sensitive columns like “Salary” or “Profit Margin” from everyone except members of the Finance team by applying CLS rules based on team membership.
DO define CLS rules using teams instead of individual users.
Managing access through teams is more scalable and less error-prone than assigning permissions one user at a time. Once a user is added to a team, all relevant security rules apply automatically.
Example:
Create a CLS rule that grants access to margin data for the “Finance” team. As new team members are onboarded, they receive the correct level of access without needing individual updates.
DO use user attributes or teams to assign row-level security (RLS).
User attributes and teams provide a flexible way to control which users can see specific rows of data, such as region- or department-specific records. Like team-based CLS, team-based RLS scales more easily than individual assignments.
Example:
Restrict access to sales records so that users only see data for their assigned region, using team-based rules that align with organizational structure.
5. Filter early and intentionally
DO filter early and with prejudice.
Removing irrelevant or “bad” data as early as possible improves both clarity and performance. Early filters prevent erroneous records from reaching downstream logic.
Example:
Filter out cancelled orders or null transaction dates immediately after loading the raw data. This helps avoid unnecessary joins or metric calculations based on incomplete records.
6. Avoid overcomplication
DON’T overuse lookups.
Lookups can seem convenient, but too many of them reduce performance and introduce complexity. When combining fields from different tables, prioritize relationships or joins.
DON’T rely on pivot tables for modeling.
Pivot tables are meant for presentation, not for defining business logic. Keep your calculations and data transformations in the data model where they can be reused and maintained more easily.
Solution:
Apply all transformations in the data model first. Then use pivot tables to format or summarize data as needed for specific dashboards.
These practices help keep your data models clean, consistent, and efficient. Whether you are building models yourself or enabling business users to self-serve, these principles will support scalable, governed analytics across your team.
Creating a Sigma Data Model
This blog focuses on what Sigma’s Data Model feature can do, rather than how to build one from scratch. If you're ready to get hands-on, Sigma provides excellent resources that walk you through the setup process step by step. A great place to start is their QuickStart guide to Data Modeling, which covers the fundamentals in an interactive format. For a more detailed reference, the official documentation explains how to create, organize, and manage data models effectively.
Unlock the full potential of your data with Sigma
Sigma’s Data Model feature is a powerful way to standardize metrics, simplify collaboration, and ensure secure, governed analytics across your organization. Whether you are just beginning to explore centralized data modeling or looking to advance an existing analytics practice, Sigma offers a flexible, scalable platform to meet your needs.
At Aimpoint Digital, we have deep experience helping organizations design and implement modern analytics solutions. Our team can support you in building a robust data modeling strategy, aligning technical capabilities with business goals, and driving adoption across teams. If you would like to learn more about how Sigma’s Data Model feature can help transform your analytics workflows, connect with us today.


.png)
