
Dataiku’s Prepare recipe contains hundreds of different methods in which you can clean, prepare and transform your data, each of these methods is known as a processor. The prepare recipe is often the first recipe applied in any flow as it has multiple processors to work with different data types (string, numeric, date, geographic etc.) and allows you to configure multiple data transformation steps in a single place. This blog highlights some of our favorite and most frequently used processors.
Transform String
Purpose: Simplifies text data cleaning and enhances string data analysis.
Text data is abundant and valuable, but it is usually messy and requires cleaning before being analyzed. Text data is often manually inputted and is prone to irregularities in spelling, punctuation, and cases. Cleaning text data can be tedious, but Dataiku’s Prepare recipe lets you start in a few simple steps.
The ‘Transform string’ processor has several modes to help you convert string values to a desired format, for example, to remove leading or trailing whitespaces which can be common with flat file inputs. You can apply these transformation steps to a particular column, multiple selected columns, multiple columns matching a regex pattern, or all columns.
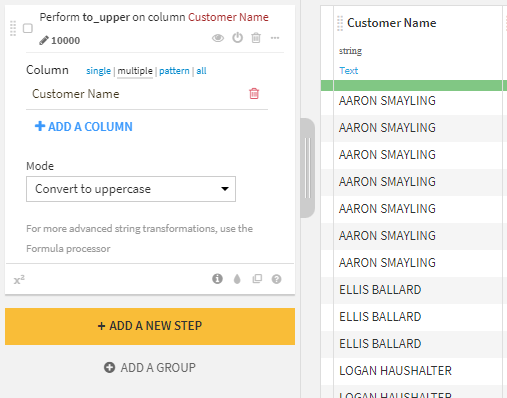
Using the ‘transform string’ tool within the Prepare recipe is a significant first step while working with string values and enables you to analyze string data further.
Merge Long-Tail Values
Purpose: Effectively reduces noise in categorical columns and can assist with model performance.
Another helpful processor for categorical columns is ‘Merge long-tail values.’ Long-tail values are categories that infrequently occur in a dataset creating noise and making analysis challenging. When working with datasets containing many types, it is common practice to maintain the most frequent variables as primary independent categories while grouping infrequent variables into a single category. This helps reduce the number of categories in the dataset, making it easier to analyze and interpret results. This noise reduction tactic can also help improve model training time and performance.
The ‘Merge long tail values’ processor is useful when dealing with messy string data. For example, a consumer complaints survey may have over a hundred unique reasons a customer issues a complaint. You must then identify the twenty most common complaints and merge the rest into an ‘other’ category. The ‘Merge long-tail values’ processor allows you to specify the number of top categories you’d like to keep and assign the replacement value for the ‘other’ categories. A similar function, but for dates, is also one of our favorite processors and is outlined below.
Truncate Date at Specific Value
Purpose: Enables easy aggregation of date fields for subsequent calculations, groupings, and reporting purposes
In reporting, there is often a requirement to aggregate data at a less granular detail than given in your data source. The ‘Truncate date at specific value’ provides a means of doing this with your date fields. For example, when working with transactional data, you may be interested in generating a report reviewing sales monthly. The raw dataset would include a separate row for each transaction, including a field indicating when the transaction occurred, for example, ‘2022-03-10T09:04:17.000Z’.
To generate the monthly report, you must understand which transactions relate to each month. Then you can apply the ‘Truncate date at specific value’ processor, specifying the ‘Date part’ as ‘Month.’ This will convert your date field to this level of detail; in this example, the value would now be ‘2022-03-01T00:00:00.000Z’.
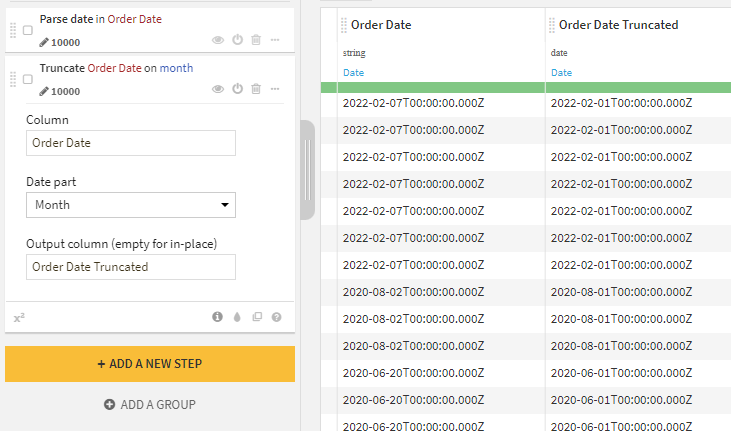
The ‘Group’ recipe can aggregate your dataset at a new level of detail by truncating the date at a specific value. Alternatively, for reporting purposes, you may reformat your date as a string, for example, ‘March, 2023,’ which can be achieved via the ‘Format Date’ processor.
Fill empty cells with previous/next value
Purpose: Quickly addresses missing data issues in datasets
Filling empty cells in datasets using a previous or subsequent value from the same column is a common practice. Dataiku’s ‘Fill empty cells with previous/next value’ processor was designed specifically for these scenarios. This processor allows users to automatically add values in the same column without creating redundant conditional statements. Data analysts commonly refer to the technique of filling empty cells in datasets using a previous or subsequent value from the same column as ‘forward/backward filling’ or ‘forward/backward imputation.’
This imputation method is often used in time series analysis and forecasting when there are missing values in the time series data. Additionally, this processor is ubiquitous when working with sparse data formats. Only filling in data for the first record of each category or subcategory is a characteristic of the sparse data format. All subsequent records for that same group are left null, making it challenging to analyze. Dataiku’s ‘Fill empty cells with previous/next value’ processor helps quickly prepare sparse data for analysis by filling in these null values.
Similarly, this processor works well when importing Excel files that contain merged cells. For example, if cells A1 through A4 include a merged cell, Dataiku will interpret A1 as filled and A2-A4 as null. This processor quickly addresses this issue by filling the null cells with the original merged value from above.
Create if, then, else statements
Purpose: Streamlines the creation of complex conditional logic in your data
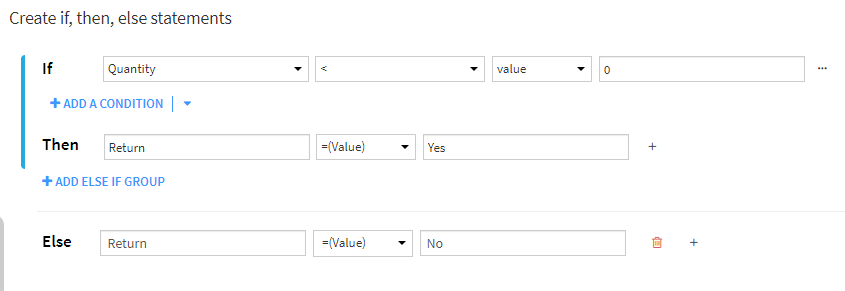
The ‘Create if, then, else statements’ processor was new to DSS 11 and has improved the ability to create conditional statements quickly and efficiently. The processor uses if, then else syntax coupled with an easy-to-use UI that allows you to build and preview your statements as you develop them. You have drop-down menus of column names for quick selections and options for adding additional conditions or groups of conditions.
Select the output column from a drop-down list or create a new column within the interface. You can also assign values using a specific value or column or create a formula that best suits your use case. Once applied, a summary is posted in the script, making it easy to review changes.
This processor is particularly useful in creating a new field based on the value of an existing field. For example, someone provided you with rules to classify customers into different buckets based on financial data. This will enable you to do a deeper analysis at the bucket level. The rules apply across a single customer and use values from several existing columns within the dataset, creating complicated conditional logic.
By using the ‘Create if, then, else statements’ processor, you can quickly translate these rules into statements and apply the result of the statements to a new column. You can also preview the results of the statements you created before applying them to the entire dataset, allowing you to catch and correct any potential errors in the logic.
Filter invalid rows/cells
Purpose: Ensuring data accuracy by removing or clearing invalid values
The purpose of this processor is simple; it allows you to drop rows or clear cell contents in cases where Dataiku has identified a value as invalid when compared with the meaning of the field as defined by the user.
For example, if I have a field containing IP addresses, and we have set the meaning as such, this processor would allow us to drop rows or clear the content of any cells that Dataiku has found do not include IP addresses.
As with many other processors highlighted in this blog, users can apply this processor against a single, many, or all columns.
Extract with regular expression
Purpose: Accelerates RegEx development and validation in your workflow
Developing regular expressions can be a long and tedious process. Generating and testing different patterns, checking matches, and finding errors are time-consuming. Usually, you can carry these steps out separately, creating a messy workflow that is difficult to maintain. The ‘Extract with regular expression’ processor changes that.
Adding the processor to your script may look like the same tedious process, but Dataiku has created a ‘Find with Smart Pattern’ interface that helps you test and validate a regular expression and can even help you build one from scratch. It is as easy as highlighting a few samples from your data, and you have a working expression in seconds.
You can see the benefits of this processor in parsing an address field for different components. For example, while analyzing customer data, you want to focus on the city that customers live in. The dataset includes an address field that contains all the address components, including the city, in a string. You could write and test a regex string for parsing this out, but the ‘Extract with the regular expression’ processor makes this much faster.
You open the ‘Smart Pattern’ interface, highlight examples of what you want to parse from your data, and Dataiku provides regex pattern options that match your examples. A ‘Match rate’ bar will show you how well the selected pattern matches the samples you have provided, and the list of patterns will dynamically update as you add more samples.
You can learn more about the RegEx capabilities in Dataiku by reading this blog.
Parse to Standard Date
Purpose: Simplifies standardization and formatting of date fields
One of the most common problems users will face when working with flat file inputs is that Dataiku will not automatically detect date or DateTime fields. The purpose of the ‘Parse to Standard Date’ processor is to convert such fields into Datiaku’s desired date format (ISO 8601 format). Once a user applies this conversion, they can perform other date-time operations upon them.
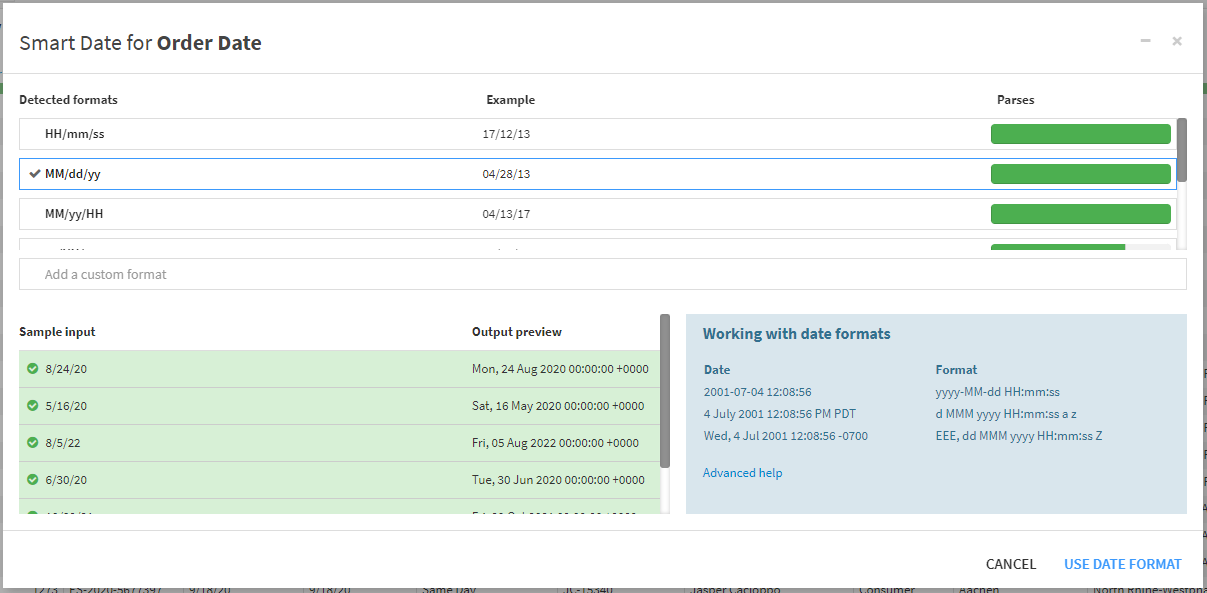
The interface for this tool allows us to choose which fields we want to apply the processor against (can be one or many) and then designate the pattern for conversion. Let’s say a user has a sample date of ’21/02/2023′. Then we would use the pattern ‘dd/mm/yyyy’ as directed by this list.
Even better, as with the ‘extract with regular expression’ processor, we can use Datiaku’s smart date feature to detect the pattern required automatically.
Fold multiple columns with pattern
Purpose: Optimizing dataset structure to support downstream processing & performance
One of the most common data transformations is folding, or transposing, a dataset. Folding transforms a comprehensive dataset with many columns into a more extended, narrower dataset.
This transformation is helpful in a few ways. Firstly, downstream aggregations (such as using the Group By recipe) are much more performant on a narrow dataset. Secondly, a folded dataset also has a much more manageable schema. For example, if you were dealing with ten different subjects, it becomes more tedious to maintain the dataset rather than having just two additional columns.
Once you add new or unknown data, this point becomes particularly important to the dataset. For example, if you have a dataset that adds a new column every quarter, you will want to fold the dataset and include any recent quarters added in the future (example below).
Dataiku enables you to identify these new columns using the ‘Fold multiple columns with pattern processor.’ Here, you can specify the regular expression to identify all the columns you want to fold rather than listing each one manually. You can even use ‘Smart Pattern’ to have Dataiku create your regular expression!
Use row values as column names
Purpose: Facilitates the use of row values as column headers in various data formats
Moving to the reporting stage of your analysis, you may encounter a situation where your data includes the names of columns you want in your final dataset as a row. This might be for several reasons:
- preparing a messy Excel or text file
- you have nested arrays in your data working with unstructured or semi-structured (i.e., JSON) data
The ‘Use row values as column names’ processor in the Prepare recipe makes updating your column names straightforward –You can simply identify the row index that contains the column names, and the processor will automatically update the dataset by replacing the existing column names with the values in that row index.
People often use this processor in conjunction with upstream data preparation processors. You might be splitting columns, sorting, and parsing data to get the row values you need (and to identify the correct index).
Ready to elevate your data processing and analytics capabilities with Dataiku? Let Aimpoint Digital be your guide!
Our team of experts can help automate your data processing and analytics reporting systems, making your organization more efficient and data-driven.
Take advantage of this opportunity to optimize your analytics processes. Contact us today by filling out the form below, and one of our specialists will reach out to you to discuss how we can tailor a solution to your unique needs. Transform your data journey with Dataiku and Aimpoint Digital – let’s get started!



.png)