.png)
The Critical Role of MLOps in Machine Learning at Scale
In machine learning (ML) projects, we frequently see organizations that are willing and able to develop models in a proof-of-concept (PoC) or minimum viable product (MVP) phase but then struggle to move these models into full-scale deployment. While initial results show promise and gain traction with stakeholders, operationalizing these ML models at scale introduces a new set of challenges for data scientists and developers.
In a recent project, our team assisted a global organization with getting a suite of forecasting models into production. The client’s team had successfully developed models that performed well in the PoC phase and wanted to roll them out across a broader number of locations, but encountered the following roadblocks:
- Tracking model improvements: During development, model iterations and performance were manually tracked and as scale increased it became difficult to consistently measure improvements.
- Scaling to multiple locations: The initial forecasting models were built using data for a few select locations, which when scaling to hundreds of locations, led to various issues, like data inconsistencies and slow run times.
- Ensuring consistency: While the PoC was well managed by the team, scaling required coordination across multiple teams and environments. Without a standardized MLOps strategy for deployment and monitoring, there was risk of deteriorating performance over time.
These types of challenges are common to any organization looking to bridge the gap between ML experimentation and production. This is where implementing an MLOps framework across the entire ML lifecycle provides several key benefits, including:
- Accelerated time to value: MLOps enables organizations to transition from experimentation to production faster through standardized workflows, CI/CD pipelines, and enhanced automation and tracking.
- Reduced redundant code development: MLOps promotes creating reusable components, resulting in reduced overhead for similar use cases.
- Enhanced management of model quality and visibility: Built-in monitoring and experiment tracking ensures teams can quickly assess model performance and identify degradation sooner.
- Ensured reproducibility of experiments: MLOps practices leverage version control for datasets, code, and model artifacts, which allows for easier revisitation and replication of experiments.
By leveraging AzureML, we were able to reap these benefits for our client while streamlining deployment and standardizing processes to ensure scalable and reliable models in production.
AzureML Architecture-at-a-Glance
The example architecture below highlights core components of the framework we developed and how we leveraged AzureML’s native MLOps capabilities for our use case. The key ML pipelines– data processing, model training, and model inference – are modularized and reusable, allowing this framework to be leveraged across all locations and efficiently modified as needed. The same data processing component is also reused by both model training and inference pipelines to ensure consistency.
By organizing the solution into modular AzureML components, we support version control, CI/CD integration, and experiment tracking, ensuring the deployed solution is scalable, maintainable, and reliable. This modular approach also enables the client to have the flexibility to swap out or enhance individual steps without disruption to the entire pipeline, accelerating innovation while simultaneously reducing risk.
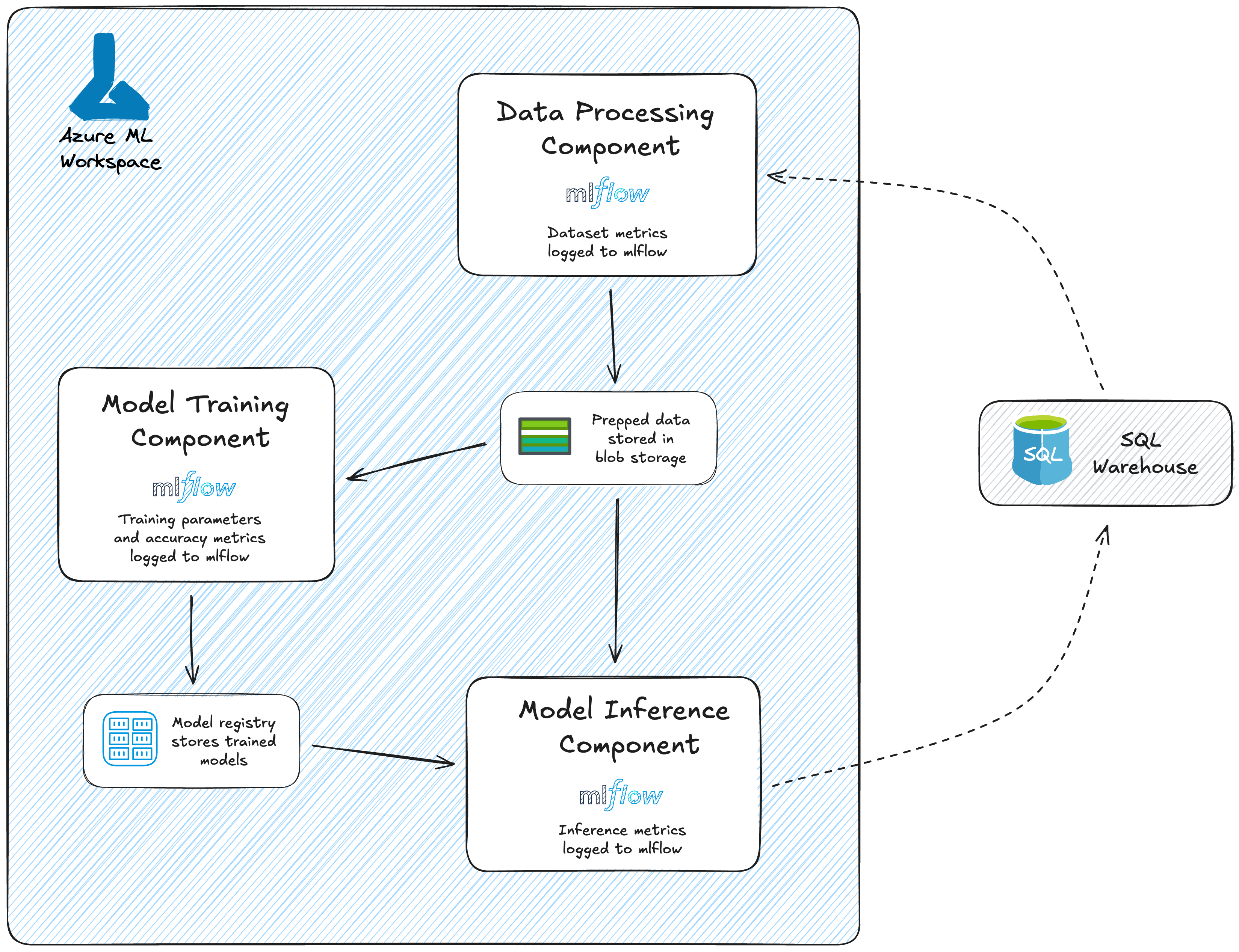
This framework embeds MLOps best practices into every stage of the machine learning lifecycle. In the following sections, we will break down the key practices that make this possible in AzureML.
Implementing Best Practices in AzureML
1. Version Control & Asset Management
In AzureML, model versioning provides a clear history of every training iteration, making it easy to track how a model evolves over time. This was especially critical for our client since each location required a tailored model and being able to store and reference multiple versions ensured updates could be deployed with confidence. This structure made it straightforward to compare performance between versions, roll back if necessary, and maintain a consistent deployment history across all locations.
AzureML’s versioning also made it possible to register each input dataset, code base, and runtime environment, guaranteeing full lineage tracking and reproducibility. This gave the team assurance that training runs were based on the correct historical data, that the codebase was consistent, and that environmental dependencies were captured.
Beyond version control, AzureML also streamlines asset management by enabling modular, reusable components that ensured the level of standardization that was required by the scale of this project. By breaking the modeling pipeline into individual components, we were able to reuse core code across locations while versioning the components independently. For example, an update to the data scaling logic in the preparation step is applied universally, avoiding having to update the code for all locations separately This practice significantly reduces redundant development and ensured consistency.
Model management is also simplified in AzureML through use of the model registry. Once a model was trained for a given location, it was registered, creating a link to the dataset, code, and environment used during training. This is invaluable for troubleshooting, auditing, and compliance, especially if a forecast needs to be explained or retraced months later.
2. Automated Processes & CI/CD Integration
AzureML’s component-based pipeline structure also better supports CI/CD integration and automation – enabling robust, repeatable, and efficient model deployment.
As mentioned previously, we leveraged AzureML components in our pipeline, such that each component encapsulates a specific task. These components were then compiled to create pipelines that could be repeatedly run in an automated fashion through AzureML Schedules. This drove value for the business team by ensuring they were always seeing the most up-to-date forecasts.
In the Azure ecosystem, we utilized AzureML alongside Azure DevOps pipelines to implement the CI/CD infrastructure using Azure Pipelines. Below is a summary of the infrastructure components that were established to facilitate a streamlined delivery of the model to the business users.
Continuous Integration (CI)
The CI is automatically enabled when changes to the code or configurations are made to the git repository. In our workflow, when new code is pushed to the GitHub repository, it automatically triggers the Azure DevOps pipeline. During this process, environment dependencies are installed, data validations are conducted, model training takes place, and ultimately, the model artifacts are securely stored in the model registry.
Continuous Delivery (CD)
Azure Pipelines also automate the way models are deployed across environments from dev to test to prod. The way this process works is the latest model artifact is retrieved and deployed to the test environment, triggering a series of automated validation and integration tests to be run. If successful, the model is then promoted to a higher environment. This ensures a standardized and repeatable process to deploy the models across environments.
3. Monitoring & Experiment Tracking
AzureML leverages MLflow for experiment tracking, a model registry for managing model versions, and built-in tools to monitor accuracy and detect data drift, ensuring models remain reliable over time.
MLflow, specifically, provides a centralized platform for tracking experiments, parameters, metrics, and artifacts. In our multi-location forecasting use case, this allowed our team to easily compare the performance of different forecasting models across locations, identify which model yielded the best results, and track the impact of changes on the forecast accuracy. MLflow also supports nested runs, which was useful for running complex experiments that involved multiple steps or sub-experiments. Furthermore, all aspects of the code, parameters, environment, and dependencies are tracked to the experiment, making the experiment easily sharable and reproducible.
Once we selected the best model configuration and trained the models for each location, we were able to use the AzureML model registry as a central repository for all models. This registry helped our team to track model versions, metadata associated with each model, and the deployment of the models.
In addition to experiment tracking and model registry with MLflow, AzureML offers built-in capabilities for detecting model and data drift in production. For data drift this works by establishing baseline reference data and conducting a statistical analysis on the reference data compared to the production data such as Jenson-Shannon Distance or Kolmogorov-Smirnov test. If data drift is detected, alerts can be set up to notify users via an email. Additionally, model drift detection is supported, which compares the distribution of the reference predictions to the distribution of predictions in production. AzureML can also track model performance by comparing predictions with true labels, helping identify when the model's accuracy declines over time and enabling the triggering of alerts when necessary.
In summary, AzureML offers a comprehensive set of features to build a robust monitoring and experiment tracking framework, supporting the entire end-to-end model lifecycle and helping maintain model quality over time.
Conclusion
Taking ML projects to production requires more than just a well-built model, it demands a scalable, maintainable infrastructure that ensures consistency and performance at every step. By implementing these MLOps best practices in AzureML, we helped our client move their forecasts beyond experimentation and into a robust deployment framework for scaling to multiple locations.
Our client was able to see the immediate value of using this framework through reduced manual effort for scaling to new locations, enhanced ability to experiment and implement improvements, and direct visibility into model performance. In the long term, the client will also be able to benefit from a maintainable and scalable system that helps lay a foundation for moving additional ML projects to production.
If your organization is facing similar challenges to operationalize and scale ML solutions, our team of experts is here to help. Contact us to start a conversation about how we can support your MLOps journey.




.png)