
In today’s data-driven world, data scientists are expected to do more than just build machine learning (ML) models. They’re increasingly responsible for also deploying, monitoring, and explaining those models in production –what previously was considered to be core responsibilities of MLOps. Yet much of their time is often spent wrestling with data pipelines, feature engineering inconsistencies, and maintaining hand-crafted SQL scripts.
dbt gives data scientists the power to streamline workflows, enforce consistency, and scale their impact. dbt is a transformation framework that lets you build modular, version-controlled SQL and Python models directly inside your data warehouse. Originally designed for analytics engineering, dbt has become an essential MLOps tool, enabling data scientists to manage feature engineering, scoring logic, and post-model outputs in a consistent, production-grade fashion.
By integrating dbt into your toolkit, you can bridge the gap between raw data and actionable insights, whether you're training machine learning models, building interactive dashboards, or powering AI-driven decision-making.
When integrated into your ML lifecycle, dbt delivers:
- Efficiency: Transform data once and reuse across Python, dashboards, and LLMs
- Consistency: Pull from the same trusted inputs across training, scoring, and reporting
- Scalability: Update logic in one place and propagate downstream instantly
- Observability: Gain tests, documentation, and audit trails for every step
This blog explores how dbt fits into each stage of the ML lifecycle—from scalable feature engineering and inference all the way to app-building, while integrating seamlessly with tools like Dataiku, Streamlit, and Python.
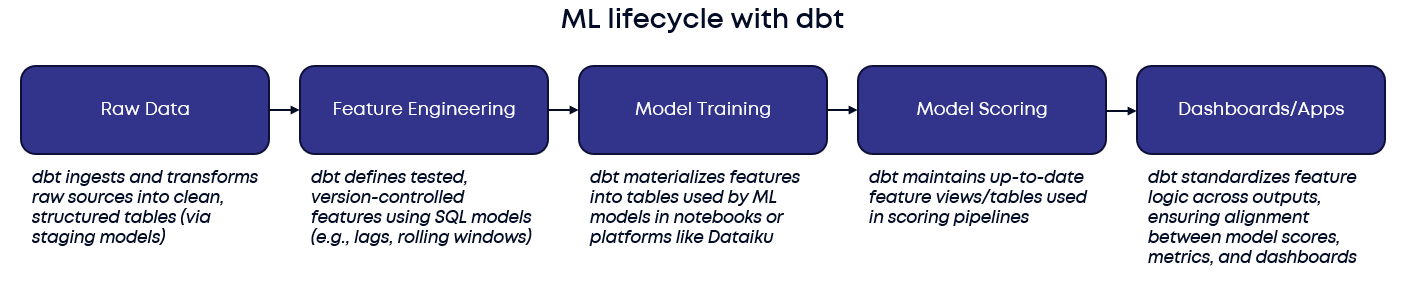
Scalable Feature Engineering
Machine learning performance is only as strong as the data that feeds it. One of the most common pain points in the ML lifecycle is inconsistent feature logic across training, serving, and retraining environments. This inconsistency, often caused by teams duplicating or rewriting feature code in notebooks or pipelines across different projects, can lead to inaccurate predictions and performance degradation, as the model is no longer operating on the same data it was trained on. dbt addresses this by becoming your feature transformation layer—with transformations defined once as modular, version-controlled SQL models. dbt makes it easy to embed tests directly into your feature pipelines, so data validation isn’t an afterthought, it’s built in. By enforcing assumptions (e.g. non-null values, uniqueness, or valid ranges) right where features are defined, you catch issues early and ensure only clean, trusted data flows into your models.
Model Scoring Made Easy
Using dbt, you can define robust, production-ready features (e.g., rolling 90-day aggregations, lagged values) as dbt models. You can then materialize them as tables or views in your data warehouse and query them from Dataiku, Python, or any platform during both training and scoring.
With dbt’s core capabilities:
- ref() to modularize and chain transformations
- built-in tests to validate nulls, uniqueness, and value ranges
- and the run scheduler or dbt Cloud jobs to automate updates
You get version-controlled, reproducible feature pipelines that are easy to maintain.
Example: Rolling Aggregation Model in dbt
--models/customer_90d_activity.sql
select
customer_id,
date_day,
sum(purchase_amount) over (
partition by customer_id
order by date_day
rows between 89 preceding and current row
) as rolling_90d_spend
from {{ ref('customer_daily_activity') }}
Once defined, this rolling aggregation model becomes a reusable asset that powers your scoring pipelines. For example, if you're generating monthly predictions (e.g., who will churn next month), you can simply query the latest version of this model, knowing it reflects the most up-to-date 90-day history for each customer. Because it's version-controlled, tested, and automatically refreshed via dbt jobs, you don’t need to rewrite SQL or manually backfill data each month-just plug it into your model scoring logic.
To support frequent model refreshes or retraining workflows, dbt also supports incremental models. These allow you to efficiently update only new data, keeping pipelines performant and cost-effective even when scoring on tighter cadences like daily or hourly.
Example: Incremental 90-Day Rolling Spend
-- models/customer_rolling_spend_incremental.sql
{{ config(materialized='incremental', unique_key='customer_id') }}
select
customer_id,
date_day,
sum(purchase_amount) over (
partition by customer_id
order by date_day
rows between 89 preceding and current row
) as rolling_90d_spend
from {{ ref('customer_daily_activity') }}
where date_day >= dateadd(day, -90, current_date)
{% if is_incremental() %}
-- Only process new days since last run
and date_day > (select max(date_day) from {{ this }})
{% endif %}
With incremental logic and scheduled jobs via dbt Cloud, you can keep features and scores reliably up to date without rebuilding full pipelines or managing streaming infrastructure.
This approach ensures your predictions are grounded in fresh, reliable data-without needing custom engineering. dbt handles versioning, orchestration, and core testing (e.g., schema changes, null checks, uniqueness) out of the box.
Pair this with business logic validations (like threshold-based tests for feature drift or freshness checks to ensure your sources are up to date), and you’ve got a feature pipeline that’s both trustworthy and auditable. It’s how data scientists build production-grade pipelines, without leaving the warehouse.
Scaling Model Outputs into Apps with dbt
Model training typically isn't the bottleneck, operationalizing features and predictions is. In many workflows, feature logic and model scores live in isolated notebooks or custom scripts that are brittle, hard to scale, and disconnected from downstream systems.
dbt addresses this by allowing you to define version-controlled, testable data models, including feature tables, scoring logic, and post-model outputs directly in your data warehouse. These models are queryable, auditable, and production-ready, enabling seamless integration across the ML stack.
Transform Once, Use Everywhere
By building your feature transformations, scoring logic, and model outputs in dbt, you create centralized assets that can be reused across:
- Batch inference jobs (via Python or orchestration tools)
- Internal dashboards (via Tableau, Sigma or Power BI)
- Interactive apps (like Streamlit, including native Snowflake apps)
- Embedded analytics or business-facing tools
This not only enforces consistency between training and inference, but it also means your model outputs can drive real-time decisions, reporting, and exploration from a single source of truth.
dbt as the Interface Layer Between ML and the Business
Instead of querying ad hoc tables or copying logic across environments, downstream tools can now read directly from dbt-curated fact and dimension models, which include, scored predictions, feature values, and metadata for explainability (e.g., feature importances).
For example, let’s say your model predicts customer churn risk. In dbt, you might have:
- A fact table: fct_customer_churn_scores
Contains customer IDs, churn scores, prediction timestamps, and important feature values used in scoring. - A dimension table: dim_customer
Contains customer-level attributes like segment, region, or acquisition source.
These are built as tested, versioned models in dbt and materialized in your warehouse:
-- fct_customer_churn_scores.sql
select
customer_id,
churn_score,
top_reason,
score_generated_at
from {{ ref('ml_scoring_output') }}-- dim_customer.sql
select
customer_id,
customer_segment,
region,
signup_channel
from {{ ref('raw_customer_data') }}
A business-facing dashboard or app can now join these models to show:
- Which customers are high risk (e.g., churn_score > 0.8)
- Why are they at risk (e.g., top_reason)
- How risk varies by region or segment
And because these tables are managed in dbt, any updates to scoring logic or business definitions automatically flow downstream, with no need to re-code filters in Tableau, Power BI, or Streamlit.
Paired with dbt’s semantic layer, you can also define key business terms like “high-risk customer” (churn_score > 0.8 and customer_segment = 'enterprise') once in YAML and reuse them across tools. This enables self-serve metric exploration, explainable AI interfaces, business-ready dashboards that align with the model’s logic.
Why It Matters for Data Scientists
- Reusability: Build features and scoring logic once in dbt and access them everywhere.
- Governance: dbt models are tested, version-controlled, and documented—unlike scattered notebook logic.
- Scalability: No need to rebuild pipelines or outputs for every consumer.
- Collaboration: Stakeholders and engineers can interact with model outputs directly, without needing access to code.
In short, dbt turns your ML workflow into a production-ready data product, one that plugs seamlessly into your organization’s ecosystem.
Conclusion
Data scientists are no longer isolated analysts, they are full-stack contributors. With dbt, anyone with core SQL skills can build robust, production-grade data pipelines, just like a data engineer. It gives data scientists the tools to own more of the ML lifecycle, from feature engineering and model scoring to AI-powered insight delivery, ensuring every step is reproducible, explainable, and built to scale. Whether you’re deploying ML models, building real-time dashboards, or enabling LLM-based applications, dbt becomes the backbone that ensures accuracy, traceability, and speed.
True data science goes beyond models, it’s about delivering reliable, transparent insights that drive confident decisions.
With dbt, your models don’t just make predictions, they power decisions. Whether you're scoring customers, driving real-time recommendations, or embedding insights in dashboards, dbt helps you scale with clarity and confidence.
But that’s just the beginning.
In another blog we’ll explore how dbt plays a foundational role in AI-powered systems—especially when paired with tools like Snowflake Cortex LLMs. You’ll see how dbt models ground LLM outputs in trusted data, make your business logic machine-readable, and enable truly explainable AI.
About Aimpoint Digital
Aimpoint Digital is a market-leading analytics firm at the forefront of solving the most complex business and economic challenges through data and analytical technology. From integrating self-service analytics to implementing AI at scale and modernizing data infrastructure environments, Aimpoint Digital operates across transformative domains to improve the performance of organizations. Connect with our team and get started today.



.png)