%20for%20Your%20Business%20Use%20Case.png)
So, you read the first blog in our application planning series and decided to move forward with a Generative AI use case but are overwhelmed by the variety of Large Language Model (LLM) options. In fact, there are a plethora of LLMs out there including GPT-4.1, Claude 3.7 Sonnet, and Deep Seek R1, and it seems like new LLMs are being introduced almost every day. It can be difficult to know where to start and which particular LLM to choose for your use case. In this blog post, we aim to make this important decision less daunting by providing a step-by-step guide on how to evaluate and select the most suitable LLM.
Our approach finds the best model by narrowing down the pool of options through a set of filtering stages:
- Model Features & Hard Constraints: Make-or-break model features, such as context window
- Standard Benchmarks: selection based on publicly available metrics
- Use Case Evaluation: Design of custom evaluations specific to our use case
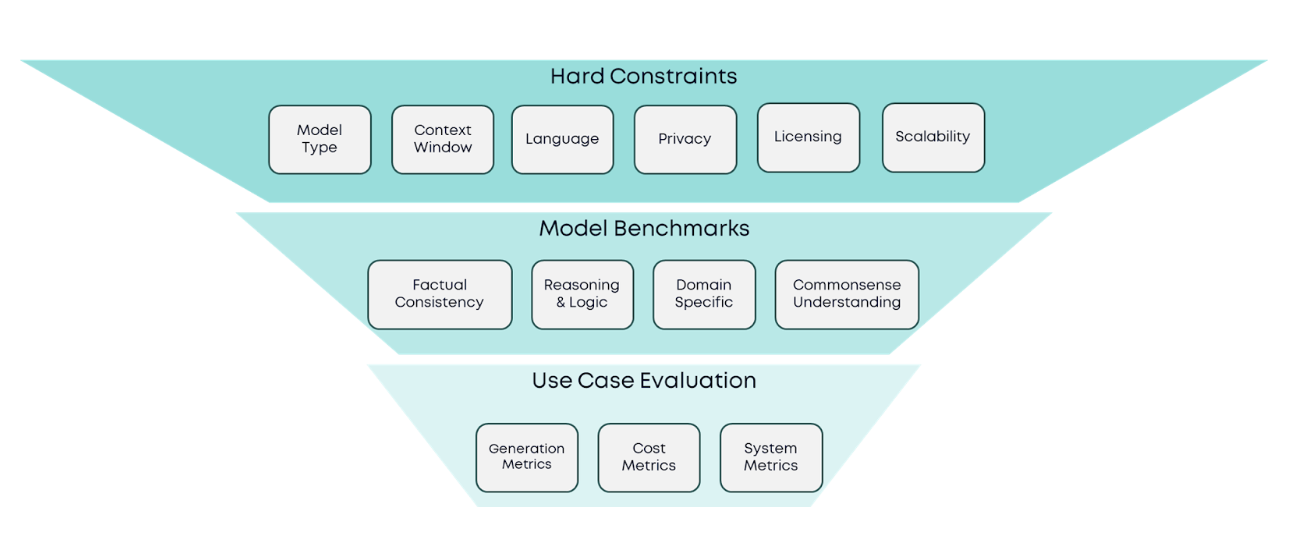
1. Model Features & Hard Constraints
Before comparing the performance of every model that exists, we should first identify the hard constraints of our application. Hard constraints are requirements that are deal breakers—if a model doesn’t meet these requirements, it’s automatically out of the running. These constraints should be our starting point, serving as an initial filter that simplifies the decision process by narrowing down the options. For instance, if our application processes long documents, a model with sufficient context length is an essential requirement, and others that lack it can be discarded without another thought.
Each use case has a different set of features that are considered hard constraints. Here is a list of important features to consider, which will help narrow down the pool of options:
- Model type:
- Embedding: map text to a vector which can be used to do similarity matches like in RAG use cases.
- Chat: conversational models generally exposed through interfaces such as ChatGPT and are great at following instructions in tasks like data extraction pipelines or general agents.
- Classification: return a label from a given label set and are cheap and efficient in classification tasks.
- Context Window: The max number of tokens an LLM can use as input to generation. A general rule of thumb is 1 word is 3-4 tokens, but this depends on the model.
- Privacy guarantees: Some LLMs might use your confidential data for training purposes; others provide stronger privacy protections. For use cases with the highest privacy requirements, such as those utilizing personal user information, consider using self-hosted models so that the data never leaves the company’s premises.
- Model licensing: When reviewing model licenses and use case requirements, be aware of commercial use permissions and restrictions on using model outputs to train other models.
- Scalability: Make sure the model service provider can support your expected traffic at a reasonable cost. Some model providers have provisioned throughput that can ensure you meet your production SLAs.
- Language support: Most LLMs support English; this is important if you need to support uncommon or regional languages.
- Function calling/structured outputs support: Consider whether your application requires JSON outputs or tool calling capabilities.
- Multi-modality: Some models can interpret and generate images, enabling applications like document understanding that require visual input.
We should now have a smaller selection of models whose features satisfy our needs. In the next section we cover how to compare their performance.
2. Standard Benchmarks
LLM benchmarks and leaderboards are essential tools for evaluating and comparing the performance of LLMs. Benchmarks are standardized tests that assess a model's capabilities, such as reasoning, factual consistency, and domain-specific knowledge. As models get more intelligent, benchmarks can become obsolete, and newer, more advanced tests are developed.
Start by choosing a benchmark that evaluates your areas of interest. These are common benchmarks sorted by the capability they assess:
Reasoning & logic
Measures a model’s ability to follow complex reasoning steps, apply logical inference, and combine multiple pieces of information to reach correct conclusions
- ARC-C: complex science questions
- MMLU: knowledge of 57 academic subjects
- MuSR and BBH: Challenging reasoning problems
- GPQA: Graduate level QA with domain reasoning
Factual consistency
Assesses how well a model provides correct, fact-based responses instead of fabricating information (“hallucinations”)
- MMLU: factual recall
- TruthfulQA: how well a model avoids misleading answers
Commonsense understanding
Measures a model’s grasp of everyday scenarios, causal reasoning, and plausible outcomes beyond formal knowledge
- HellaSwag: predicting plausible sentences or scenario completions
- WinoGrande: Complex pronoun resolution requiring common sense
Domain-Specific
Focuses on performance within specialized areas of expertise, where terminology and problem structure differ from general language tasks
- LegalBench: law
- MedQA: medicine
- OpenBookQA: science
- GSM-8k and MATH: mathematics
If you are only considering models within a single provider, for example, OpenAI or Anthropic, their documentation reports internal metrics to explain the capabilities of their in-house models. Given that these metrics can be biased, it is recommended to use neutral benchmarks/metrics when comparing models across big providers.
3. Use Case Evaluation & Cost-Performance Tradeoff
By now, we should have narrowed the field to a small set of models that look suitable for the use case. The final step is a more detailed assessment to determine which one actually works best in practice.
Before we start a full evaluation, it’s worth checking whether the task is even a good fit for an LLM at all. A simple way to do this is to test the top-performing model first: if the strongest model cannot handle the task, it’s unlikely that smaller or cheaper ones will succeed.
LLMs excel at some tasks but fall short on others. This is why a feasibility check is essential before investing effort into detailed comparisons.
For this final evaluation, we design a custom test that reflects the use case. This begins by identifying the evaluation metrics that actually matter. A common approach is to use LLM-as-a-judge, where one LLM scores another model’s responses against a ground-truth dataset of queries and expected answers.
Metrics typically fall into two groups:
Generation Metrics
- Answer Accuracy: Does the LLM’s response align with the ground truth? Exact matches work for math, but text tasks benefit from LLM-as-a-judge, which assesses semantic similarity instead of word-for-word matches.
- Answer Relevance: Is the generated answer relevant to the user’s question asked? This metric looks for concise on-topic answers to user queries.
- Faithfulness: Is the answer generated based on the retrieved documents? This metric helps ensure answers are grounded in the truth and avoid hallucinations in RAG applications.
- BLEU (Bilingual Evaluation Understudy) evaluates how well a model translates text from one language to another.
- ROUGE (Recall Oriented Understudy for Gisting Evaluation) is used to assess the performance on a summarization task.
Cost and System Metrics
- Input/ Output Token Size: The input token size typically includes the user query, prompts, and context. The output token is the LLM generated response and can be limited by setting a max token size for most LLMs. The general rule of thumb is the greater the input/output token size, the greater the cost.
- Latency: The time it takes from the user’s request for the GenAI application to return a response with a fully generated text. This is a critical component in driving user experience. If latency is really long, you may want to consider LLMs that have token streaming capabilities.
- Time-to-first token (TTFT): The time it takes from the user’s request for the first token to be generated in the response.
- Token Throughput (tokens/s): The number of tokens are processed by the LLM per second. Depending on the usage patterns, length of the input and output tokens, a larger throughput may be required.
Once we have our evaluation dataset and metrics, we should iteratively test cheaper or less powerful models until we find the sweet spot of acceptable performance at a reasonable cost.
As a rule of thumb:
LARGER MODELS → BETTER PERFORMANCE → HIGHER COST
The easier the task, the more you can save by using a smaller model. The diagram below offers an approximate ranking of task difficulty for LLMs..
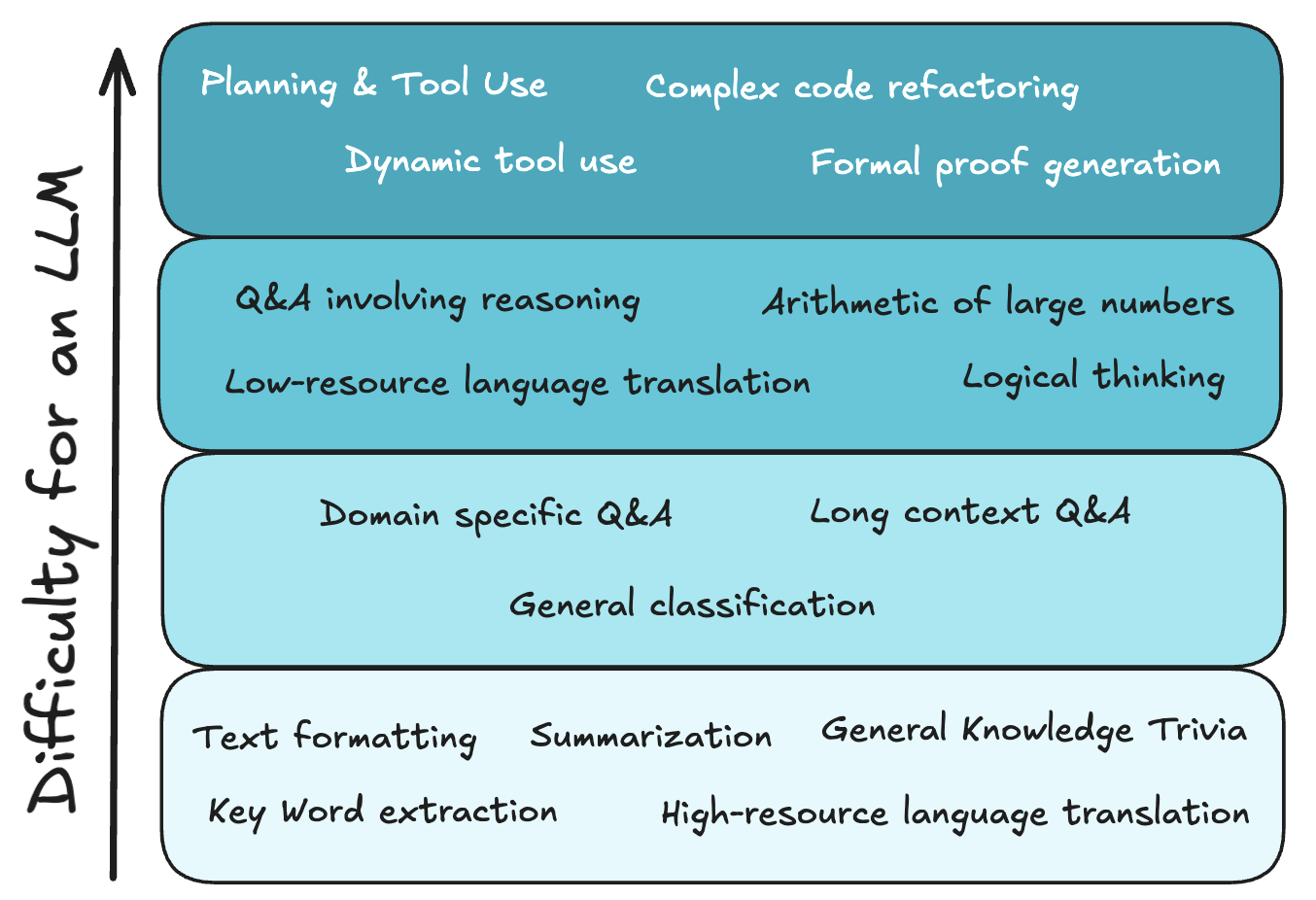
Conclusion
Selecting an LLM can be challenging; but it does not have to be. Let’s recap our step-by-step approach to LLM selection:
- Consider hard constraints and discard unsuitable models
- Compare publicly available standard benchmarks to narrow down the list
- Devise your own evaluation and find the sweet spot between cost and performance
Our team at Aimpoint Digital can provide guidance on GenAI best practices, including LLM model evaluation and selection.
In our next blog in the AI Application Planning series, we will do a deep dive into two important decision points: when it makes sense to finetune an LLM, and when to use external versus in-house LLMs.
Unlock the power of GenAI
Leverage our technical GenAI expertise to support and accelerate your organization's GenAI strategy. Whether you're just getting started or looking to scale, we can help you identify, prioritize, and implement high-impact GenAI use cases tailored to your business goals.
Our team can support you in your GenAI journey – from ideation to production—to ensure you get the most out of your GenAI investments.
Interested in learning more? Reach out to one of our experts today!
Who are we?
Aimpoint Digital is a market-leading analytics firm at the forefront of solving the most complex business and economic challenges through data and analytical technology. From integrating self-service analytics to implementing AI at scale and modernizing data infrastructure environments, Aimpoint Digital operates across transformative domains to improve the performance of organizations. Connect with our team and get started today.



.png)