
A familiar pattern is playing out in organizations that have otherwise done the right things with data. Warehouses are in place, dashboards are widely used, analytics teams produce regular reporting, and governance exists on paper. Yet natural-language querying still feels unreliable. When leaders ask why the chatbot cannot simply be trusted to answer straightforward business questions, the discussion often drifts toward models, prompts, or vendor choices.
That focus is usually misplaced. Language models are increasingly competent at generating queries. What they struggle with is meaning. If a model cannot reliably infer what “revenue”, “active customer”, or “the Northeast” means in your company, it will still return an answer, and it may sound persuasive but it may also be wrong.
An AI-ready semantic layer addresses that gap. It sits between raw data and end users, translating technical database objects into business-friendly concepts. In practice, it is the discipline of making business data legible to an agent that must translate natural language into structured logic, while navigating the ambiguity in how people actually ask questions.
Three layers, three levels of usability
It helps to separate the data stack into three layers that are often blurred together, because different ways of organizing and modelling data are designed for different kinds of consumers. Some structures are built to support repeatable reporting: the same metrics, the same dimensions, and the same questions asked every week. Others are built to support interpretation: taking a vague business question and deciding what it should mean in structured terms.
This is where the gap shows up. BI tools are deterministic, i.e., a dashboard sends a known query and receives a known result. An AI agent starts with free-form language, constructs a query dynamically, and has to make judgment calls about what the user meant. That requires deeper semantic richness and context than most BI-oriented semantic layers were built to provide.
You can see why by looking at how each layer evolves business meaning as data moves “up” the stack - from messy system output to analytics-ready models, to the context an agent needs to interpret intent.
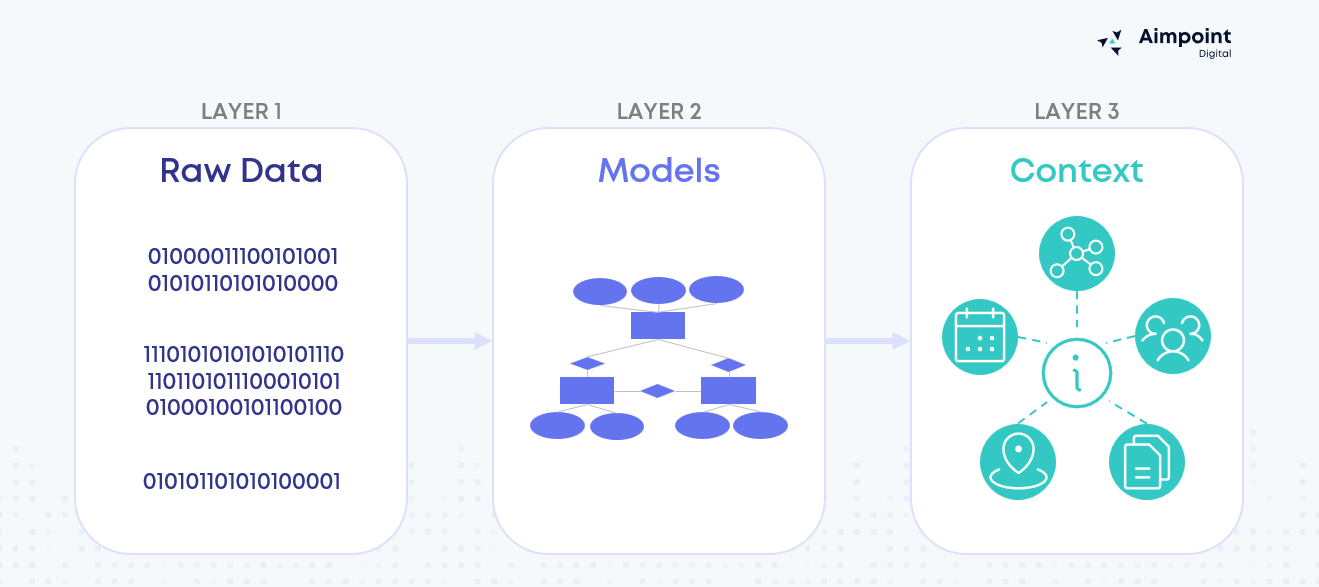
- The first is raw data: operational extracts, events, billing records. It is essential, but it is rarely designed for analysis. It contains internal codes, competing definitions, and timing quirks that make sense to source systems but not to business questions.
- The second is the modelling layer most organizations already have in some form: curated tables, dimensional models, dbt models, cubes. This layer makes it consistent. It standardizes calculations and creates consistent definitions so that BI tools can query deterministically. Dashboards work because they run known queries against known fields. They do not have to decide what the user meant.
- The third layer is institutional knowledge – it makes questions interpretable. If a human analyst or an agent receives a question like, “How are we doing in the Northeast this quarter?”, they have to resolve what is implied using context, such as which region hierarchy is standard, which definition of performance leadership cares about, and how the fiscal calendar is applied. Without this layer, the system can query data correctly but still answer the wrong question, because it cannot reliably disambiguate intent.
An AI-ready semantic layer is a structured way to supply that context, so agents can interpret intent without improvising your business logic.
What “AI-ready” really means
The most useful analogy is onboarding. A capable junior analyst can write SQL on day one. The harder part is learning how the business talks, which definitions are accepted, and which interpretations are misleading. An AI-ready semantic layer is how you encode that institutional knowledge so the agent can ask and answer questions the way your organization expects.
In practice, AI-readiness is less about a checklist of artifacts and more about encoding meaning alongside structure.
It starts with shared language. Businesses use overloaded terms, and we usually resolve the ambiguity unconsciously. “Customer” might mean an account or an individual. If the semantic layer does not make that mapping explicit, the agent will guess or ask too many clarifying questions.
Next is metric truth, including grain and time logic. Many wrong answers are definition errors. If “active” means 28 days in one context and 90 in another, the system needs a clear, governed definition tied to the metric itself.
Then come relationships and safe paths. When an agent builds queries dynamically, it can choose joins that look plausible but distort results. The semantic layer should make correct relationships explicit and define what it is safe to slice a metric by.
Finally, you need defaults and guardrails, because users are routinely vague. If a question does not specify a calendar, a region definition, or a version of a metric, the system should know when to apply a default and when to push back.
Examples help too, but only when they capture genuine conventions. The goal is not to train the model with trivia, it’s to encode how your organization typically interprets recurring questions.
Turning AI-readiness into real work
Once you accept that the problem is meaning, the work becomes much less mysterious. One of the more persistent misconceptions around AI for BI is that it requires rebuilding existing data infrastructure. In our experience, that is not usually the case. Most of what separates a successful natural-language experience from a frustrating one is not a new warehouse or a new model. The work involved in making data AI-ready is predominantly traditional analytics engineering, so things like cleaning up metric definitions, resolving naming inconsistencies, and documenting business logic that has lived in people’s heads rather than in code. You do not need to rebuild what you already have. You need to make it legible.
The AI-specific enrichment on top of that foundation, such as aliases, canonical filter values, and Q&A pairs, is relatively thin by comparison. It helps an agent map the words people use to the concepts you have defined, but it cannot compensate for inconsistent definitions or undocumented logic underneath.
AI has a way of forcing this conversation because it removes the guardrails that dashboards quietly provide. A dashboard can look consistent because it shows one approved view. An agent, by design, explores more of the space. Wherever definitions conflict, dimensions are ambiguous, or joins are unclear, it will surface the gaps quickly, and it will do so with confidence unless you have constrained it.
This matters for sequencing and resourcing. If the underlying semantic layer is inconsistent or undocumented, adding AI tooling on top of it does not help. It simply surfaces governance gaps faster. That is why “AI-ready” should be thought of as a data quality and governance upgrade that happens to unlock a better user experience, not the other way around.
What it unlocks
An AI-ready semantic layer does more than improve chatbot accuracy. It creates the conditions for AI to become a reliable interface to the business, rather than just a novelty layered on top of reporting.
When business meaning is explicit, governed, and accessible to agents, organizations can unlock:
- More trustworthy self-service analytics, because natural-language questions resolve to governed definitions instead of improvised logic
- Faster access to answers, especially for leaders and business teams who should not need an analyst or dashboard specialist for every question
- Greater consistency across teams and tools, since dashboards, analysts, and AI systems all draw from the same definitions and relationships
- Lower risk of confident but incorrect answers, through guardrails around metrics, joins, filters, and defaults
- A stronger foundation for broader AI use cases, from conversational BI to embedded copilots and workflow automation that depend on shared business meaning
The immediate value may show up in a chatbot or natural-language interface. The larger value is much broader: a semantic foundation that allows AI to scale without trading accuracy for convenience.
What’s next
This first post has focused on why an AI-ready semantic layer matters: not because AI suddenly makes semantic modelling optional, but because it makes gaps in business meaning impossible to ignore.
In the next post, we will show what an AI-ready semantic layer looks like in practice, including the components teams actually build and maintain. In the final post, we will walk through the implementation roadmap we have used with clients, from choosing the first domain to scaling across the business.




.png)